
一种可用于普通PC摄像头的手势检测与识别算法
2021-05-28 07:05佟喜峰
绥化学院学报 2021年5期
佟喜峰 樊 鑫
(东北石油大学计算机与信息技术学院 黑龙江大庆 163318)
近些年来,随着信息技术的不断发展,手势识别技术作为新型的人机交互方式得到了广泛的研究与关注,但是目前手势识别并没有得到广泛的应用,主要原因是大多都需要昂贵的专用摄像头和传感器设备,比较常见的是Kinect传感器和深度摄像头。王攀等通过Kinect传感器对手势的深度图像进行获取,进而追踪手势的骨骼关键点,再利用动态时间规整算法(DTW)进行识别,取得了不错的识别效果[1]。有多位研究人员研究基于成本较低的基于普通PC摄像头的手势识别,取得了较多成果。张勋等人提出一种静态手势检测网络模型ASSD,该模型基于深度学习的SSD方法,将原方法的特征提取网络VGG16用改进的卷积神经网络Alex Net取代,取得了较好的识别效果[2]。沈雅婷通过深度学习提取多层网络简化的高价值易用特征,通过向量的表示简化了算法[3]。利用深度学习的方法进行手势识别的确可取得较好的识别效果,但也存在一些问题,例如训练时间比较长,需要比较多的学习样本,在识别速度上会略慢,而且还需要性能比较好的PC设备。针对上面存在的问题本文采用普通PC摄像头进行视频的获取,采用肤色分割法结合背景差分法的方法对手势进行分割,采用动态时间规整算法(DTW)进行实时识别。本文采用的方法没有用到深度学习,只需要普通的PC机就可以流畅地运行。实验结果表明本文的算法在实时性和准确度方面都取得了比较好的效果。
一、手势检测算法
手势跟踪的整体流程如图1所示。由于图像可能会受到光照的影响引起色偏以及饱和度不足的情况,从而影响最终手势分割的效果,因此在得到了视频图像之后,先采用色彩平衡算法对视频图像进行处理。本文使用的是王朝辉等人提出的色彩平衡算法[4],该算法可以在一定程度上消除光照引起的视频图像色彩不均匀的情况。接下来利用肤色检测的方法来获取视频图像中的肤色区域,肤色检测常用的方法有三种,分别是基于RGB、HSV和YCbCr颜色空间的肤色检测。对比实验结果表明YCbCr得到的肤色检测的效果最为良好。虽然基于RGB的效果也不错,但是速度较慢,不满足实时检测的要求。因此选择了基于YCbCr颜色空间的肤色检测方法。采用基于YCbCr的方法首先需要把RGB颜色空间转换为YCbCr颜色空间,转换公式如公式(1)-(3)所示。
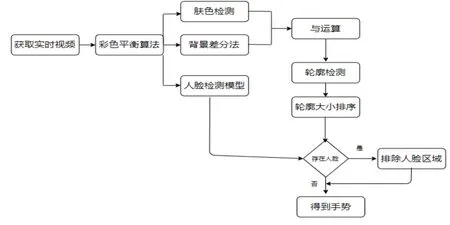
图1 手势跟踪算法流程图

基于YCbCr颜色空间的肤色检测算法的算法步骤为:
(1)利用转化公式将图像从RGB颜色空间转到YCbCr颜色空间;
(2)利用opencv的split函数分别将转化后的图像的Y、Cb和Cr颜色提取出来;
(3)将提取出来的Cr颜色空间做高斯滤波;
(4)对Cr进行二值化,得到二值化后的肤色区域。
在得到肤色区域之后,一般会存在一些噪声。为了避免噪声对后续处理产生影响,需要进行降噪处理。本文通过数学形态学的闭运算,即先做膨胀再做腐蚀,达到降噪的目的。接下来利用背景差分法获取动态的前景区域。背景差分法是一种摄像头静止的条件下获取运动目标的方法[5-6],它的原理是利用当前帧和背景图像差分从而得到运动区域。背景差分法首先要选取视频序列的前N帧图像做平均得到背景图像。假设f(x,y,i)表示第i帧图像,b(x,y,i)表示根据第i帧图像之前的N帧图像求得的背景图像,公式(4)给出了b(x,y,i)的计算公式。假设d(x,y,i)表示第i帧差分图像,则d(x,y,i)的计算公式如公式(5)所示。在获得差分图像后,通过阈值化操作获取二值化后的目标。
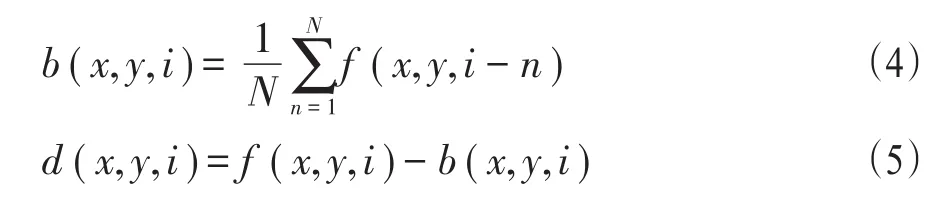
图2给出了利用该方法检测运动目标的算法,图3给出了背景差分的计算结果。

图2 运动目标检测算法
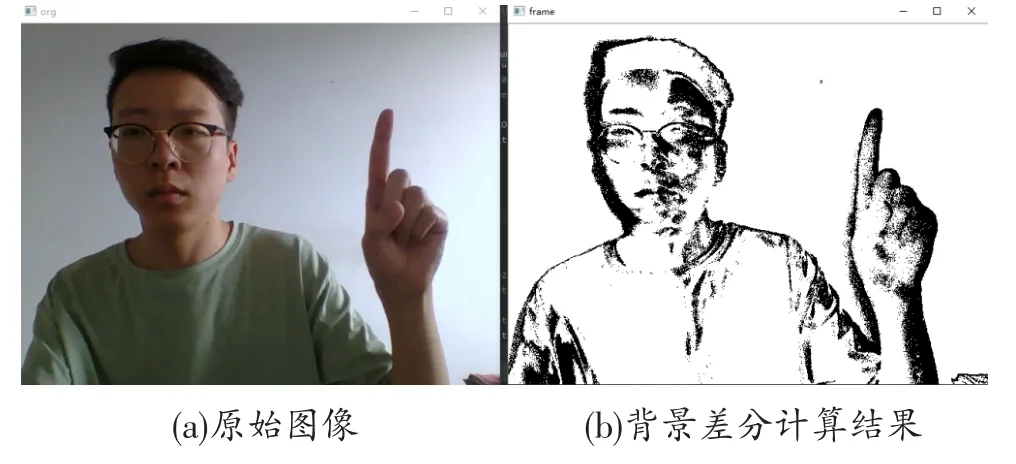
图3 背景差分的计算结果
因为头部做不到完全静止的状态,因此人脸存在时人脸也会被检测出来,这样就得到视频中的运动目标区域。设肤色检测后的视频图像为A,背景差分法得到的是B,那么将两者二值化后做与运算就可以将背景中禁止的类肤色区域剔除掉,得到运动区域res=A&B。图4给出了肤色分割和背景差分做与运算结果。图4(a)为原始图像;图4(b)为肤色分割的结果;图4(c)为肤色分割和背景差分做与运算的结果。由图4可见,墙上的包已经被剔除掉。
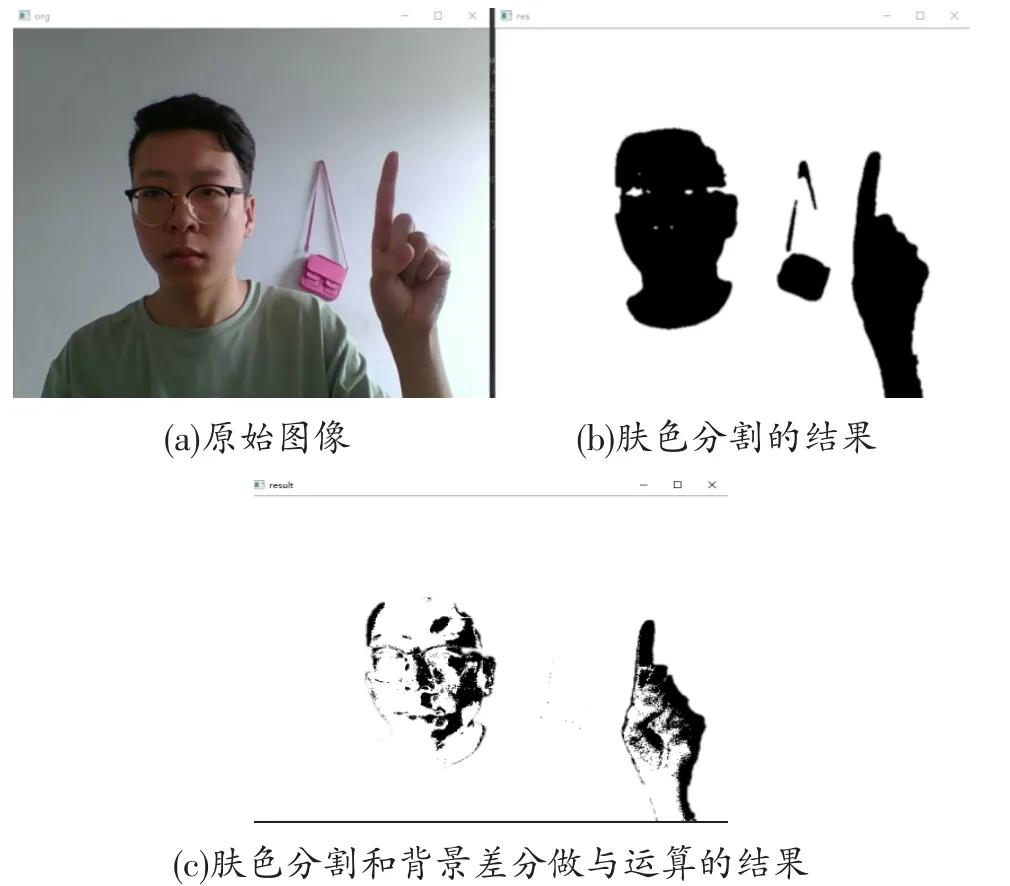
图4 类肤色区域剔除的结果
经过图像分割后,只剩下运动的手部区域和可能出现的较小的噪声区域,如果存在人脸,人脸也会被检测出来,当头部存在时应去除头部区域。去除头部区域的方法是利用人脸检测模型进行检测[7-8],从而判断人脸是否存在并记录人脸所在区域的位置,为后面剔除人脸区域做准备。接下来要用边缘检测算法对上面得到的运动区域res进行轮廓的提取。一般情况下,边缘点的周围既有白点也有黑点,对二值图像的像素点进行遍历,当遍历到黑色点的时候,判断这个点的四周是否全为黑色点,否则,说明该点为边缘点。图5给出了轮廓提取算法。

图5 轮廓提取算法
在得到的肤色检测的图像中,一般情况下里面包括人脸、手势和一些较小的噪声区域。通常情况下在人脸存在时手和脸是面积最大的两个轮廓,人脸不存在时手是面积最大的轮廓。接下来对图像的所有轮廓按面积进行排序。如果在前面的步骤中检测到人脸,则标记人脸的位置,选取除人脸外的最大轮廓作为手部区域。如果在前面的步骤中没有检测到人脸,则直接选取最大轮廓作为手部区域。图6给出了手部区域检测的算法。图7给出了手部的检测结果。

图6 手部区域检测的算法
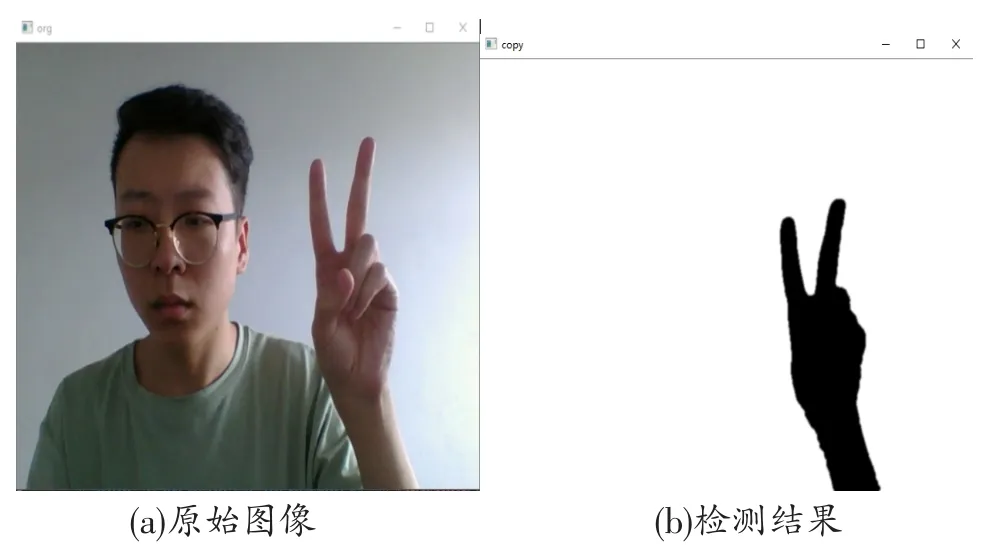
图7 手部检测结果
二、手势特征提取
为提取手势特征,需要先提取手势轮廓。首先利用数学形态学的膨胀和腐蚀运算消除大部分的噪声点和空洞区域,然后利用边缘提取算法将轮廓提取出来。具体的边缘提取的规则为:如果某个点为黑像素点,如果该像素点的上下左右四个邻近点有白点,则把当前黑像素点置为白色。
在得到的手势轮廓上提取如下特征:(1)各个轮廓点到中心点的距离;(2)相对曲线高度。为计算各个轮廓点到中心点的距离需要求取各个轮廓点的坐标,但是当一个手势轮廓和模板手势的大小相差太大时,那么轮廓点与中心点的距离会发生较大的变。如果把这些距离作为特征,变化的距离会导致识别准确率的降低。所以要提前进行大小归一化,将待识别的手势轮廓与模板手势轮廓归一化成相同的周长。假设某个轮廓点的坐标为(xi,yi),手部中心点坐标为(xc,yc),那么(xi,yi)与(xc,yc)的距离di为:
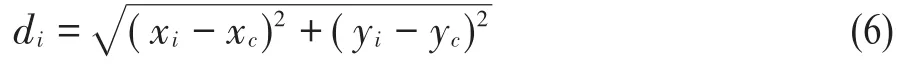
算法需要根据公式(6)计算出每个轮廓点到中心点的距离。以各个轮廓点到中心点的距离为曲线高度,则相对曲线高度是指曲线当前高度与当前邻域内曲线高度平均值的差值。相对曲线高度的绝对值越大,表明在当前位置曲线越弯曲。
三、基于DTW的手势识别
DTW算法,即动态时间规整算法[9-11],它能够对两个整体形状类似,但长度不一致的时间序列在时间轴上进行动态的扭曲,从而用来计算两个时间序列的相似性。对于两个手势,当发生较大形变时,该算法也能取得比较好的识别效果。分别对模板手势和待识别手势提取相对曲线高度特征,然后利用DTW算法计算匹配距离,最终以最小匹配距离所对应的模板手势的类别作为识别结果。
四、实验结果及分析
为了验证本文提出的手势分割算法的有效性,我们将本文的方法和以下两种方法进行了对比:基于椭圆肤色检测模型的方法;基于YCbCr和OSTU[12]相结合的方法。图8给出了实验结果的对比情况。
从图8可以看出,基于椭圆肤色模型的手势分割和基于YCbCr和OSTU结合的手势分割得到的结果比较相似,会受到人脸和类肤色区域的干扰,均不能得到单独的手部区域,本文的方法可以得到单独的手势,剔除掉其它的类肤色区域。手势分割算法的好坏在于能否从复杂环境中把手势单独提取出来,通过对比实验表明本文的方法具有较好的分割效果。
本实验将ASL数据集[13]中的手势作为模板手势,分别从ASL手势数据集的数字‘0’到‘9’选取五张不同的图片,为了满足实时性的要求,避免在识别时才提取模板图片的特征从而导致识别速度过慢。因此要提前对这些手势图像进行特征进行提取并放在文件中,在识别时直接读取文件中的特征数据。准备工作完成以后,通过测试者在Pc机前实时的对数字0-9十个数字分别做了二十次实验测试。得到的识别准确率如表1所示,从表1可以看出总体的识别准确率可以达到90%,表明本文的识别算法对实时检测到的手势具有较高的识别准确率。

表1 手势识别的准确率
实验用到的PC设备主要参数如下:CPU为Intel i7-4900m,内存为16G。测得识别每个手势需要的平均时间为0.1秒,可以满足实时识别的要求。
五、结论
本文提出了基于普通PC摄像头的手势识别算法,该算法包括基于肤色检测和背景差分法的手势跟踪、手势特征提取、基于DTW的手势特征识别等几部分内容。实验结果表明该算法在跟踪效果、识别准确率和识别速度方面均能取得较好效果。
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31
文学港(2021年12期)2021-02-28
疯狂英语·新悦读(2020年4期)2020-06-18
好孩子画报(2020年3期)2020-05-14
小天使·四年级语数英综合(2019年9期)2019-11-09
红领巾·萌芽(2019年9期)2019-10-09
小学科学(学生版)(2018年12期)2018-12-19
小学阅读指南·低年级版(2017年6期)2017-06-12
中国医疗美容(2015年1期)2015-07-12
中华皮肤科杂志(2014年4期)2014-12-19
