
一种差分演化Q表的改进Q-Learning方法*
2023-08-30 09:04曹子建贾浩文郭瑞麒
西安工业大学学报 2023年4期
李 骁,曹子建,贾浩文,郭瑞麒
(西安工业大学 计算机科学与工程学院,西安 710021)
路径搜索是人工智能领域中的一个重要问题,涉及到诸如自动规划、运动控制、资源分配、游戏策略等诸多应用场景。在路径搜索问题中,通常需要在状态空间中找到一条最优路径,以满足某些约束条件或优化目标。针对不同的问题,可以采用多种搜索算法进行求解,
目前已有的路径搜索算法有很多,例如人工势场方法[1]、蚁群算法[2]等,但这些传统搜索算法在实际应用中面临着挑战和限制。而强化学习类型的方法能够自主探索未知环境模型,以提高路径搜索问题的求解效率和精度,故该方向成为了近年来的研究热点。
强化学习(Reinforcement Learning,RL)作为人工智能领域的一个重要分支,已经得到广大学者的高度认可,在解决序贯决策问题上,强化学习采用马尔可夫决策过程的方式,智能体通过与环境交互得到经验集于当前状态进行决策[3]。而Q-Learning作为一种经典的无模型强化学习方法[4]非常适合求解有限空间的路径搜索问题,其收敛能力主要取决于智能体对环境信息的探索与利用。而在优化Q-Learning探索能力方面,不同研究人员提出了多种改进方法。文献[5]引入了探索因子和深度学习因子来提高算法的探索效率,但忽略了算法的可拓展性和稳定性;文献[6]通过势场优化Q表初值,并采用多步长策略和动态调节贪婪因子来平衡探索与利用,但未考虑动态障碍物的避障策略;文献[7]提出了使用平均奖赏和相对值函数的值迭代方式来加速收敛,但计算复杂度较高且对奖励信号不敏感;文献[8]将资格迹概念融入Q-Learning中,提出了Q(λ)-Learning算法,减少了Q值的计算量,但缺乏实验验证;文献[9]提出了Double Q-Learning算法,通过使用两个估计器分离最优动作和最大Q值的选取,改善了收敛速度;同样,Speedy Q-Learning(SQL)和Double Speedy Q-Learning也对Q值的更新方式进行了改进,提高了收敛能力[10-11],但这些方法通常需要更长的训练时间;除此之外,许多学者考虑Q-Learning与演化算法结合优化的模式,将演化算法的思想融入Q-Learning中,并从多个角度对算法存在的问题进行了优化。文献[12]提出了一种结合退火算法(Simulated Annealing)中的Metropolis准则的Q-Learning改进算法(SA-Q-Learning),利用模拟退火的思想对ε的取值进行线性控制,从而保证算法更加快速找到最优策略,但并未发挥出演化算法的优势。文献[13]为了解决不确定性的POMDP近似最优解问题,在基于SA-Q-Learning算法的基础上提出了一种有限步历史信息与状态信度概率分布相结合,提出了一种直接进化策略的新算法(MA-Q-Learning),该算法提高了算法的收敛速度,但存在Q值过估计的问题。在实际工程应用中,文献[14]针对虚拟作业中存在的不确定性问题,提出了一种遗传算法(Genetic Algorithm,GA)结合Q-Learning算法进行最优策略选择的策略规划模型(GA-Q-Learning),该模型有效地避免了早期较大的Q值动作,但该模型鲁棒性较差,无法有效地解决行为空间较少的问题。
上述改进算法能够提高Q-Learning算法的性能,但均未考虑Q-Learning算法在初始化时的盲目性,这会导致Q-Learning算法在前期路径搜索中长时间地无效探索,影响算法的收敛速度和平均回报。基于此,文中提出了一种利用差分演化(Differential Evolution,DE)算法对Q表进行优化来改进Q-Learning收敛能力的方法DE-Q-Learning。该方法利用演化算法优化Q表的初始化,解决了Q-Learning算法在初始环境中的盲目性问题。通过使用差分演化算法推动Q表的进化,DE-Q-Learning在时间和空间上提高了算法的探索效率。最后在复杂迷宫环境、实验环境Pacmman游戏和OpenAI的gym工具包中MountainCar上进行了仿真实验,实验结果显示DE-Q-Learning算法相比于Q-Learning及其改进算法具有优异的性能,并且能够在更短的时间内快速收敛。
1 基础理论
1.1 Q-Learning
Q-Learning是一种基于时序差分的无模型学习方法,其Q-Learning的核心是Q表,Q表的行和列分别表示State和Action的值,用Q表的值Q(s,a)来衡量当前状态采取动作a的价值,所以Q-Learning只考虑当前状态st以及当前状态选择的行为at,使Q(st,at)值最大即可,智能体采用Q-Learning算法与环境交互如图1所示。
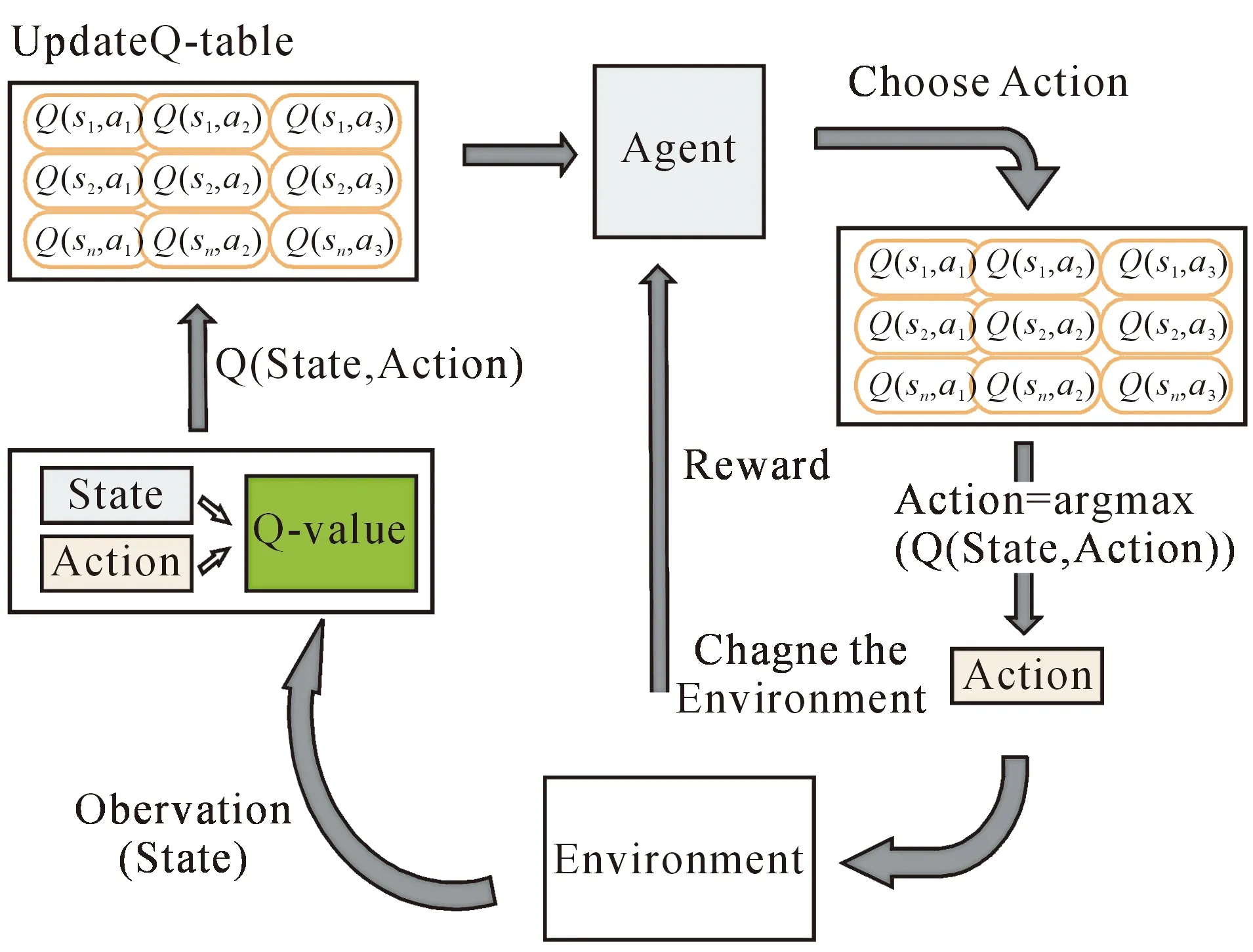
图1 Q-Learning算法与环境交互过程
通过这种局部映射的方式,无需充分地计算全局信息,只需通过局部选择的方式便可获得全局最优动作序列,进而使智能体获取最大目标收益。Q-Learning的算法伪代码如算法1所示。
算法1 Q-Learning伪代码
初始化环境E,状态空间S,动作空间A,折扣因子γ,Q表Q-table
Fork=0,1,…,mdo #agent的每条完整路径
初始化 状态s
Fort=0,1,2,3,…,do #agent的每一个训练步
通过贪心策略εof π在环境E中采取动作A
r,s′=Step(A) #执行下一个动作A产生奖励r和下一个状态s′
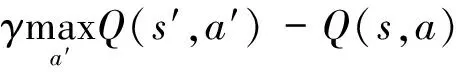
s←s′
end forsis terminated
end for
π*(s)=argmaxQ(s,a) #根据Q表更新策略
Q-Learning的状态行为值函数更新为
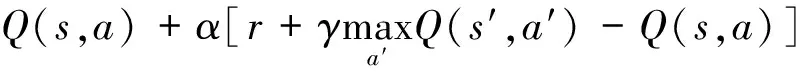
(1)
式中:s为当前状态;a为当前状态s所采取的动作;α为学习率;r为在当前状态s下执行动作所得到的立即回报。γ为折扣因子,用来控制将来累积回报对当前状态所产生的影响。s′表示当前状态s采取动作到达的后续状态,a′为在状态s′下选择的动作,然后用新的Q值去更新Q表。
Q-Learning分别采取两种不同的策略来进行策略评估和更新。在策略更新上Q-Learning采用ε贪心算法来选择动作,在更新Q表时则采用贪心算法,通过下一个状态的最大Q值来更新当前状态的值。而在动作选择中,Q-Learning采用ε贪心算法,其主要思想是在探索的同时也能同时进行一定的利用。在行为选择时采用的ε-贪心算法,其中ε值越大则探索的效果越好。反之,若ε值越小则更加注重利用。但正因为其ε取值的固定,往往不能更好地平衡其探索和利用的效率,ε取值的不合理同时也会使得算法的搜索效率大幅度下降,在实际案例中ε一般在[0,0.1]区间内取值。
1.2 差分演化算法
差分演化(DE)算法自1996年由文献[15]提出后,在解决优化问题上有着广泛的适用性。DE算法在遗传算法的启发下提出,其思想与传统演化算法保持一致,主要由变异、交叉、选择这三个步骤所组成,在解决NP(Nondeterministic Polynominal)难问题上有着良好的适用性。对于求解以下形式的最小化问题。
minf(x)
s.t.x∈Ω∈RD,
(2)
式中:D为目标解空间的维数;Ω∈RD则为可行解集。DE算法关键步骤为
Step1:变异
(3)
Step2:交叉
(4)
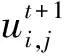
Step3:选择
(5)
通过选择操作将适应度值较好的个体进行保留,并作为下一代种群的初始值。
2 演化优化Q表的改进Q-Learning方法
马尔可夫模型作为强化学习与演化算法共同的理论基础,其定义如下:通过创建一个五元组

图2 MDP结构
2.1 时间复杂度分析
Q-Learning作为一种无模型算法,样本复杂性T决定了其时间复杂度O(T),空间复杂度O(SAH)更多取决于状态和动作的空间大小。其中S代表状态空间大小,A代表动作空间大小,H则表示为每一次执行所走的步长[16]。而在解决无模型问题上,Q-Learning在已知状态空间和动作空间的前提下,如何有效地利用环境信息是提升算法收敛能力的关键。随着模型环境复杂度的提升,不仅状态、动作对的数量增加,而且智能体在每次探索时所需的步长H也会随之增加。由此可以看出,环境信息对算法的运行效率起着至关重要的作用。
演化算法作为一种解决复杂问题的有效手段,可以用于解决强化学习在算法初期的盲目探索性问题。DE具有较低的时间复杂度O(NP-D-Gmax)[17-20],其中NP代表种群大小,D表示维度,Gmax为算法最大运行代数。对于复杂无模型问题,若将状态行为值函数Q作为NP的输入,S作为D的输入,步长H则在搜索空间进行了提升。每当演化算法生成一代Q表种群作为NP输入时,步长H在空间上则扩展为NP*H,由此便提高了算法的执行效率。由于DE算法具有控制参数少、收敛速度快、寻优精度高及鲁棒性强的优点,因此文中选用DE作为演化算法实例。当然任何其它演化算法都可以作为实例算法来对Q-Learning进行优化,文中主要侧重于DE-Q-Learning算法的原理。
2.2 算法的局限性
在Q-Learning算法运行初期,Q表参数的初始化会导致采集到的数据往往是未经训练的样本集。如何更加有效地提升算法的执行效率,更多程度取决于算法前期的探索能力。另外,在算法前期的探索阶段,所获取到的立即回报值不一定对算法训练有效,能够正确引导智能体进行决策的立即汇报过少,无法有效地帮助算法在前期快速收敛。同时,对于大多数问题模型而言,若属于密集回报型问题,则对算法的训练相对较好。但遇到稀疏回报问题时,大多数的状态转移对可能始终无法获得有效的回报值。这样便导致算法重复了很多盲目的训练,既浪费了时间也得不到令人满意的效果。
2.3 演化Q表的初始化方式
在Q-Learning算法中,Q表的初始化通常为一个全0矩阵,所以在模型探索初期存在较大的盲目性而导致算法无法快速的收敛。如何有效的初始化Q表信息对算法收敛起到了强有力的推动作用,但在无模型问题上,往往只能以随机的方式来初始化Q表信息,这未必会对算法的收敛能力起到促进作用。Q表由状态和动作的映射所组成,若初始化得到一个合适的Q表,这无疑在很大程度上加快了算法的收敛速度。可以将该问题转换为一种组合优化问题,采用演化算法的方式来寻求一种最优解,最优解的输出代表最合适的Q表。将一个Q表视作种群中的个体,通过随机初始化若干Q表来构成演化种群NP,并采用特定的评价标准保留优良个体,较好的Q表个体中的状态-动作值满足较好的组合方式。 随着演化的进行,状态-动作值的最好组合方式将被找到并作为Q表的初始化信息。图3给出了个体与种群的设定形式。
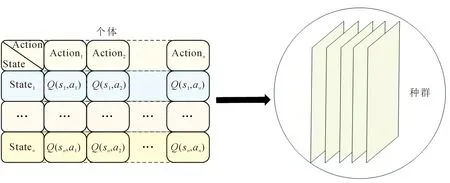
图3 个体的创建过程
这样便产生了多个并行的解空间。基于以上方式利用演化算法生成与目标函数相关的高适应度初始种群,从而可以充分探索问题的解空间,极大地提高算法前期的探索效率。
2.4 DE-Q-Learning理论思想
在求解无模型问题时,Q-Learning采用时序差分(Temporal Difference,TD)思想来进行策略更新,通过行为值函数计算公式对当前Q表进行更新,如此反复地进行“收集-利用-更新”这一过程来找寻最优策略。对于每一步状态转移所产生Q表的更新,都将直接或间接影响后续策略的选择。由于算法在更新迭代时,对先前信息存在较大的依赖性,而在探索初期,若收集到的环境反馈信息较少,则会使算法陷入盲目勘探中,无法有效获得更加具有指导性的环境信息。
图4描绘了以DE算法为例所提出的一种新型优化算法(DE-Q-Learning)。这里从宏观层面表述了DE-Q-Learning的通用性,并重点阐明了算法的独特性。在算法框架的设计上,文中提出了一种通用的方法,使其可以自由更换演化算法类型以满足在不同问题下Q-Learning的适用性。
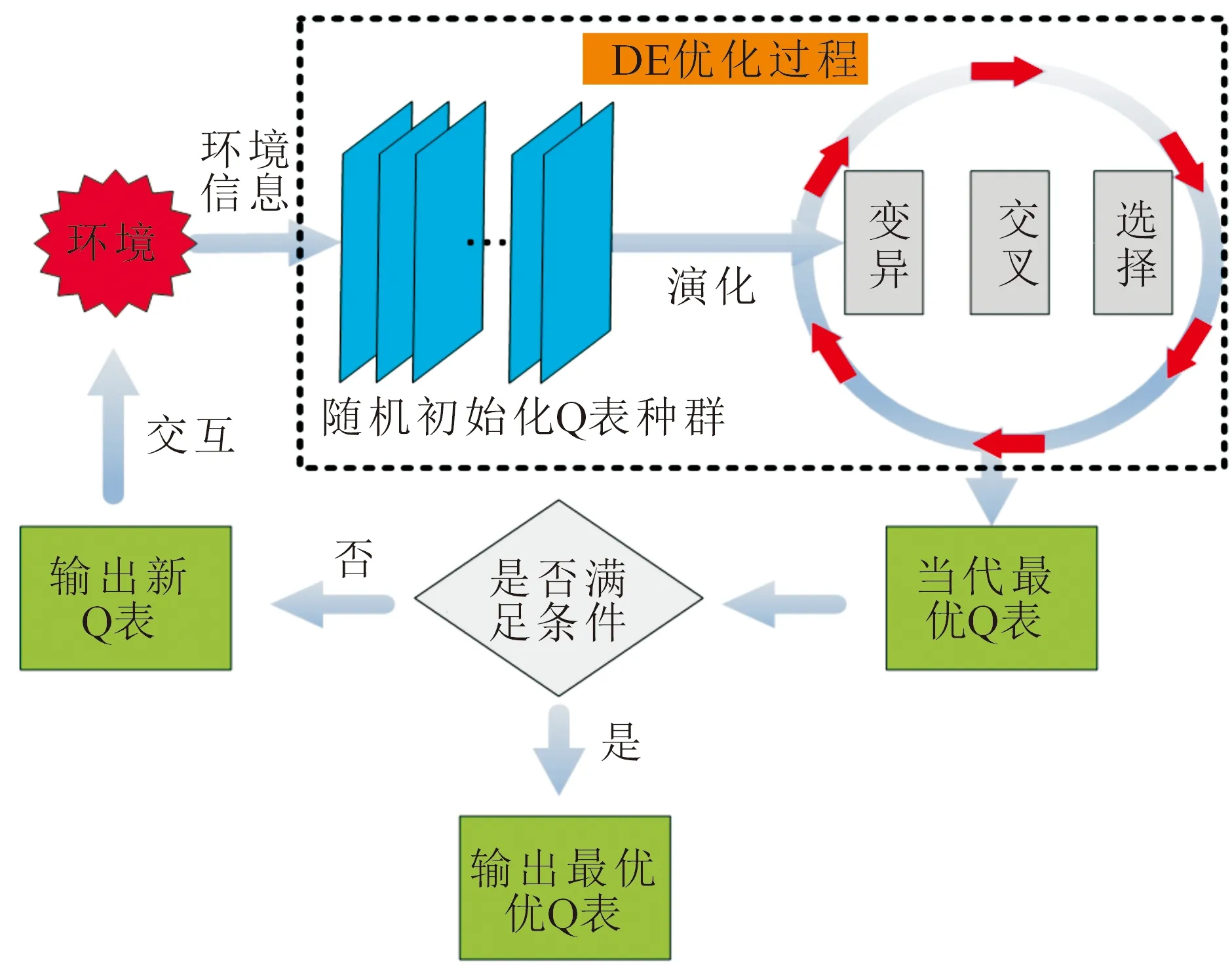
图4 DE-Q-Learning算法流程
对比Q-Learning与DE-Q-Learning可观察到,在初始化Q表时,两者最大的区别在于同一时间所更新Q表的数量。DE-Q-Learning在空间层面出现了更加丰富的并行解集,极大程度优化了算法的执行效率。与此同时,由于在优化过程中Q表种群信息是随机初始化的,在使用演化算法对其进行优化后,输出较优的Q表时总会伴随着有效Q值的存在。
对于如何使用DE算法来优化Q-Learning,需要重点解决表示方法、个体的定义及评价函数设定问题。由于不同的演化算法对应的演化过程不尽相同,这里重点突出优化的思路和方式,而不针对演化算法的具体搜索过程展开对比描述。
山地车(MountainCar)问题是强化学习中的经典问题,如图5所示,小车在一条一维的轨道上,位于两座“山”之间,目标是开车上山,但是一开始小车的发动机不足以直接行驶上山,所以需要来回行驶增强动力以达到目的。接下来在MountainCar中进行实验来验证DE-Q-Learning算法的理论假设。

图5 MountainCar 游戏环境
1) 表示方法的设定
在问题的设定上,将Q表作为演化种群NP,最终将得到一个最优个体作为Q表的输出。在MountainCar游戏环境和大部分强化学习环境中,回报值的定义均为实数形式,最终计算得到的Q值也为实数形式,所以这里采用实数编码形式作为演化算法的个体编码以及函数值表示方法。小车的参数见表1。
表1 MountainCar-v0参数
2) 演化个体的设定
在个体的定义问题上,Q-Learning算法中的Q表思想上均可以视作为一个状态动作对应值的二维列表。随机初始化若干Q表作为演化算法中的初始种群,并通过不断地演化来更新种群中的个体信息。在山地车问题中,Q表的内容由状态-动作对应的Q值组成构成,根据游戏的回报将Q值初始化在[-2,0]之间。根据表1,小车的观测值Observation是20×20的二维表格,表示小车的速度与位置,将其作为状态,而动作集是由3个离散动作组成的一维表格,故整个Q表是状态×动作的三维表格。
3) 适应度函数的设定
在演化算法中,适应度函数的设定取决于优化问题的目标。而在解决强化学习问题时,针对不同的问题模型制定不同的评价函数是解决问题的最佳手段。在MountainCar游戏环境中,回报设置很简单:如果小车到达山顶终点的旗帜(Position=0.5),则奖励0;如果小车的位置低于0.5(Position<0.5),则奖励-1。
基于以上设定,文中在MountainCar游戏环境中对DE-Q-Learning进行验证,并且使用传统Q-Learning以及它的改进SA-Q-Learning与Double-Q-Learning进行对比,其中Double Q-Learning主要思想是采用双估计器的方式来解决Q-Learning的过估计问题,SA-Q-Learning则优化了算法探索和利用之间的权衡关系。算法使用的参数见表2,超参数无具体单位,可以根据具体情况进行调整和优化,“-”代表该算法不使用此参数。
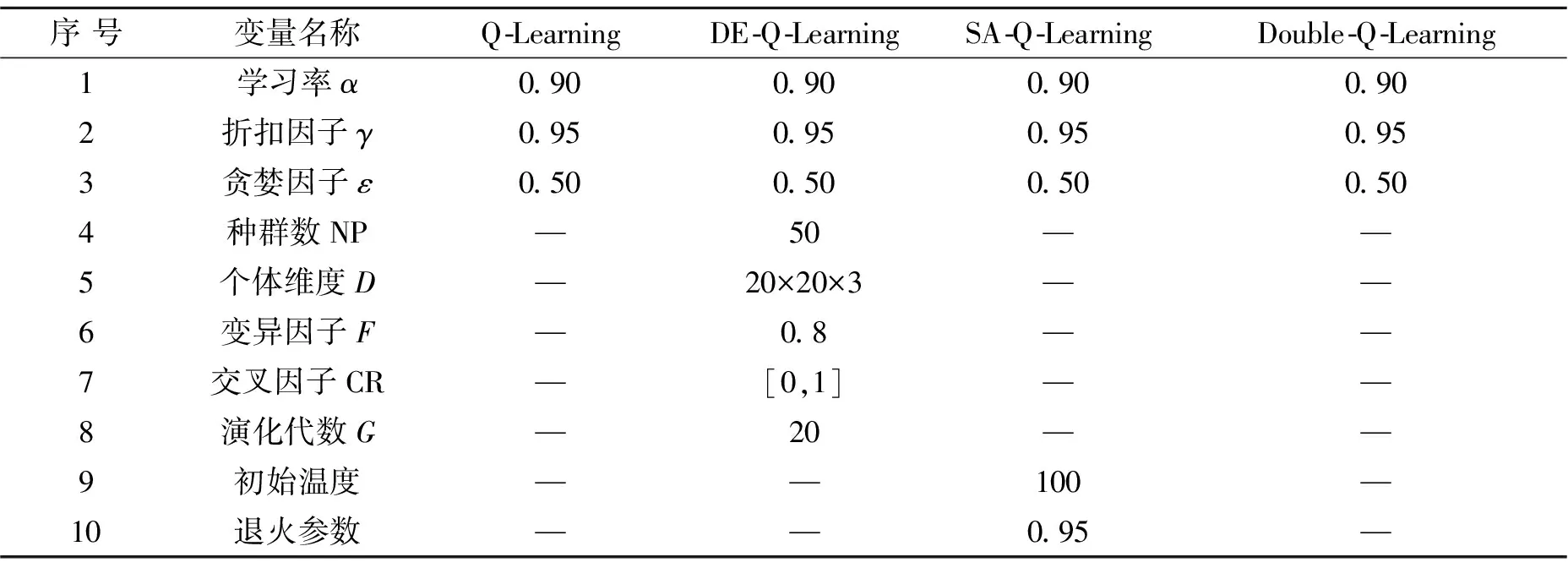
表2 MountainCar环境各算法实验参数
每种强化学习算法在该游戏环境迭代2 000次,将每代回报取平均、最大、最小的实验结果如图6~7所示。根据实验结果可以看出DE-Q-Learning算法的累积回报在训练的各个阶段都要大于原始Q-Learning算法以及它的改进算法,并且收敛速度明显快于其他算法,这是由于DE-Q-Learning算法在训练开始前就已经获得了DE算法优化出的最佳Q表,使得智能体在与环境的交互过程中能够根据状态选择出Q值最大的动作,说明DE-Q-Learning应用于此类二维状态空间有限的环境中是很有效的。为了达到在输出最优个体时不影响实例模型中Q表变化这一目的,文中提出的DE-Q-Learning算法在演化Q表时取极小运算值来初始化种群,这样既达到优化的目的,又将无关干扰因素降至最小。
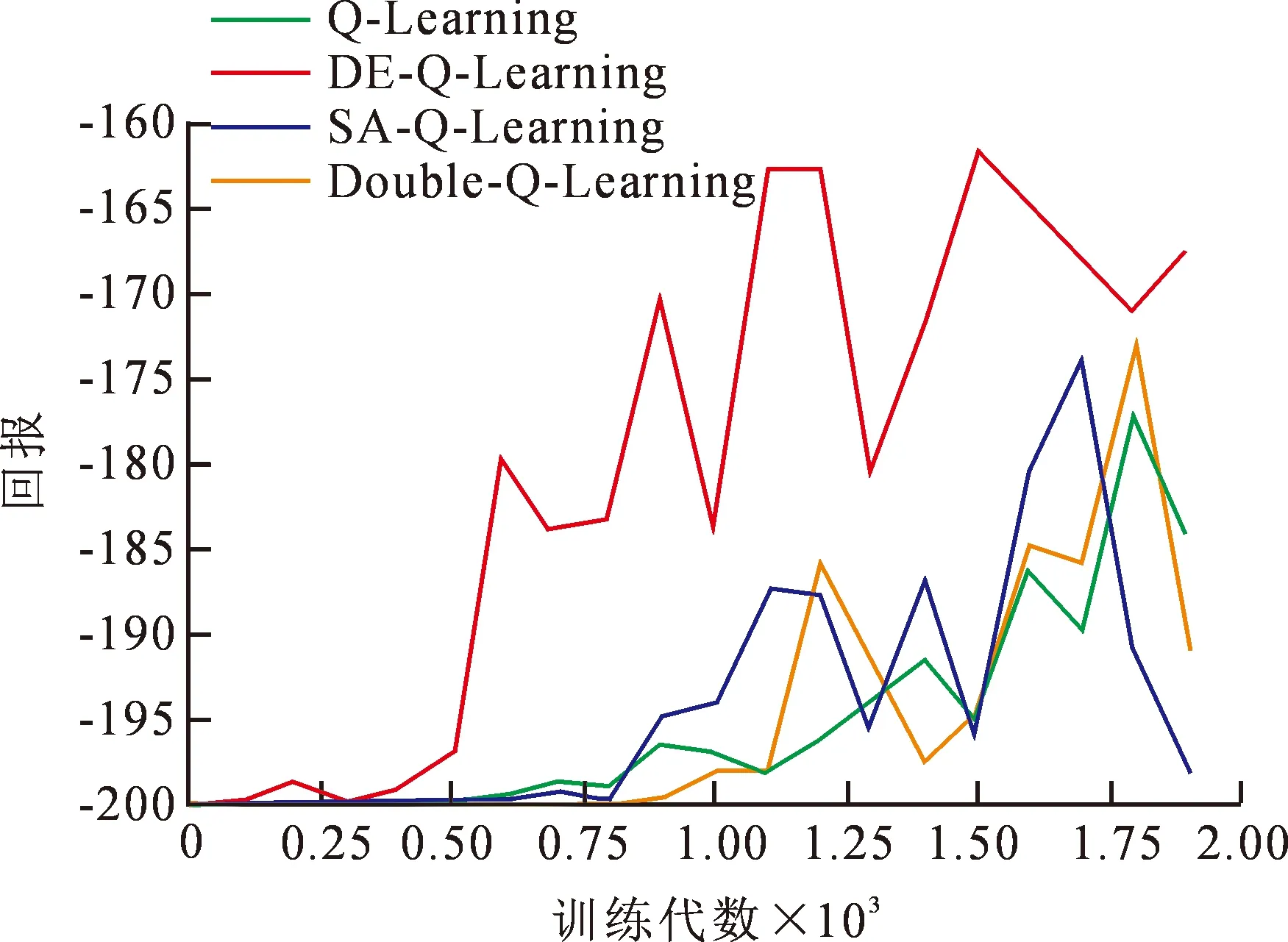
图6 MountainCar环境下算法的平均回报
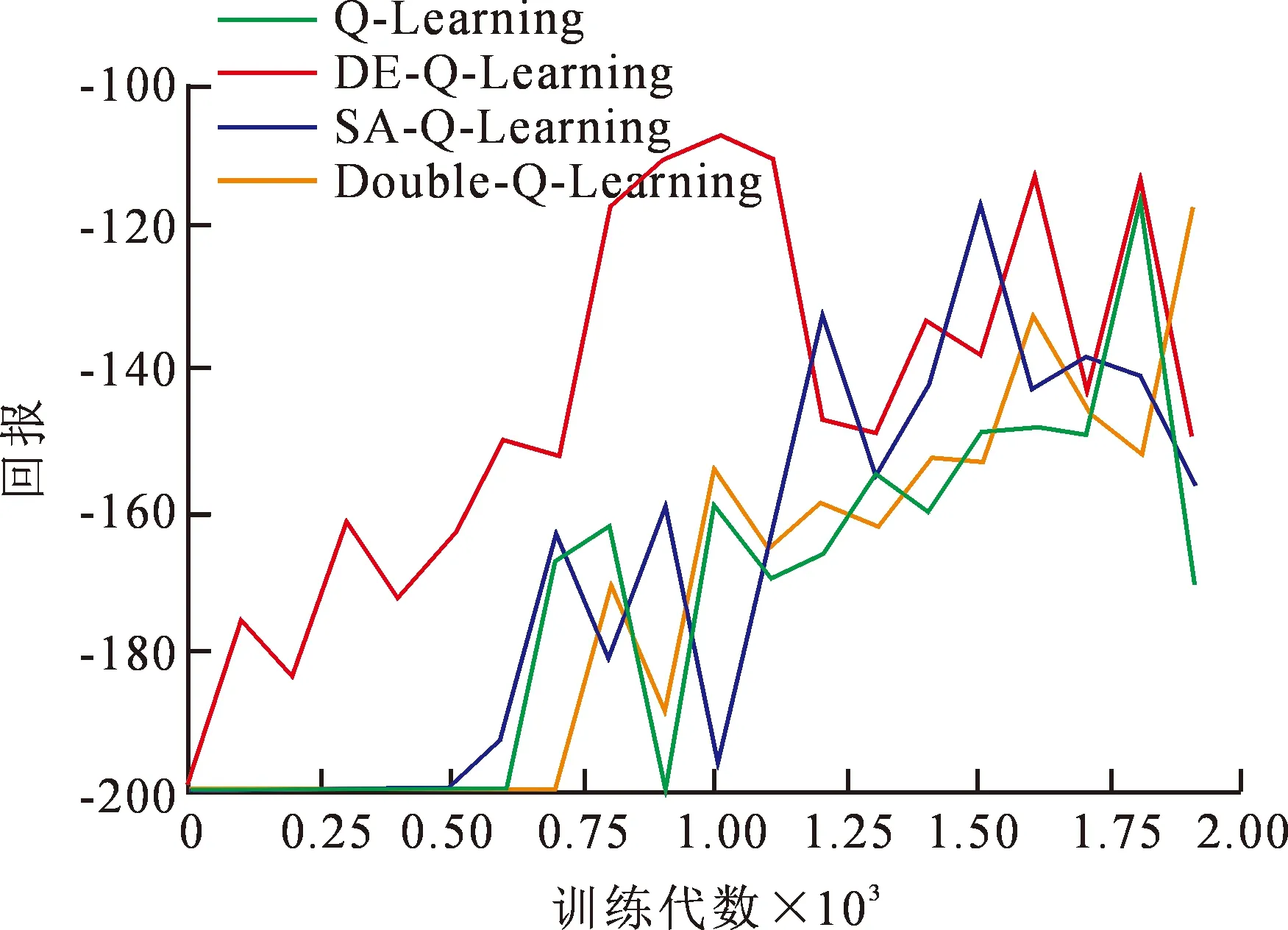
图7 MountainCar环境下算法的最大回报
2.5 DE-Q-Learning算法流程
根据2.4对DE-Q-Learning算法的理论阐述做出验证证明其是有效的,该算法的核心在于使用DE算法演化得到最优Q表,智能体能够根据Q表中的最优Q值来选取能够获得最大的收益的动作,DE-Q-Learning算法描述如下:
Step1:初始化。针对不同问题模型构建相对应的环境信息,使用随机初始化的方式构建若干Q表作为种群中不同个体:
Qi=rand(D,U)i=1,2,…,NP,
(6)
式中:Q为数量对应种群个数NP,(NP=1,2,…,n),其编码形式采用实数编码方式;D,U为特定环境Q值的最小最大值。rand(D,U)随机生成指定范围内的Q值来构成Q表种群。
Step2:计算种群中每个个体的适应度fitness,并找寻最优个体Qi及最大适应度值bestfitness。
Step3:(变异)DE/rand-to-best/1/bin为文中所采用的变异算法。
vij(t+1)=Qr1,j+F·(Qbest-Qr1,j)+
F·(Qr2,j-Qr3,j),
(7)
式中:i,r1,r2,r3∈{1,2,…,NP};j∈{1,2,....,D},且r1≠r2≠r3;Qr1,j,Qr2,j,Qr3,j表示从Q表种群中随机选取的Q表个体;Qbest代表当代最优个体。通过以上步骤得到一个变异后的种群vij。
Step4:(交叉)采用二项式交叉的方式得到新的种群uij,令A为条件“rand(j)≤CR”,B为条件“j=random(i)”,则交叉个体为
(8)
Step5:(选择)计算交叉后种群u的适应度值ufitness,并与初始种群的适应度值fitness进行比较从而挑选出优良个体作为下一代的初始种群。
Step6:判断是否达到所需精度或最大迭代次数,若满足,则终止循环并输出最优个体。否则,返回步骤2。
Step7:将最优个体作为Q-Learning的初始模型输入,通过训练找到最优策略。
DE-Q-Learning的伪代码如算法2所示。
算法2 DE-Q-Learning伪代码
Q表种群的随机初始化
Qbest=DE(q_table_population) #最优Q表由DE算法演化
输入:环境E,状态空间S,动作空间A,折扣因子γ
Fork=0,1,…,mdo #agent的每条完整路径
初始化状态s
Fort=0,1,2,3,…,do #agent的每个训练步
通过贪心策略εof π在环境E中采取动作A
r,s′=Step(A) #执行下一个动作A产生奖励r和下一个状态s′
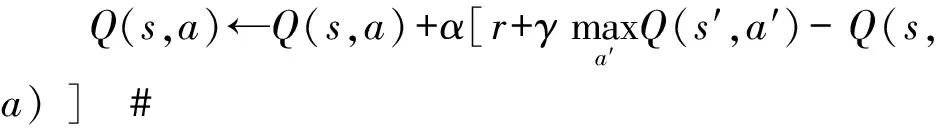
s←s′
end forsis terminated
end for
π*(s)=argmaxQ(s,a) #根据Q表更新策略
3 实验与分析
为了进一步验证文中提出DE-Q-Learning的性能,文中采用两种不同的二维迷宫环境进行实验,这类游戏有两个特点:① 动作维数小,状态维数大。② 具有明显胜利和失败的条件,且奖惩区别明显,适合验证Q-Learning改进算法的通用性和泛化能力。
3.1 复杂迷宫环境
3.1.1 实验环境
在如图8所示的复杂迷宫环境中,分别对三个算法的收敛性能进行对比实验。具体实验仿真环境为:16 GB RAM,512 G硬盘,2.60 GHz 64位处理器,Windows 10操作系统,使用Matlab2018b仿真软件。

图8 实验迷宫环境
3.1.2 环境状态设定
为了凸显出算法在稀疏回报状况下的高效性,该实验环境设定如下。设定黑色区域为墙体,代表不可达状态,模型左下角绿色区域为迷宫起点,即智能体的初始位置。模型右上角对应的蓝色区域则为迷宫出口,代表终止状态。模型中共有376个可抵达的状态,智能体在除终止状态的其余位置上回报值R均为0,在抵达终止状态时,回报R设定为100。之所以将模型的反馈情况设置为稀疏回报,其目的是为了突显出DE-Q-Learning算法的高效性。当积极回报仅存在于终止状态时,只有通过智能体反复地探索直至抵达目标状态从而不断地更新Q表,才能促使算法收敛。这一过程起初可能是盲目的,智能体在毫无先验信息的基础上进行探索无疑增加了算法的运行时间。
3.1.3 适应度函数以及评价指标
由于需要更加直观的评价标准即找到迷宫出口的次数,若在规定的步长下,智能体到达终止状态的次数较多,则说明此时的Q表具备较好的环境信息。所以针对文中实验所涉及的问题,将适应度函数设定为在指定步长下目标状态命中次数,即
f(x)=
(9)

f(num)=
(10)
(11)
式中:t为算法运行代数;num为智能体在t代时累计目标状态命中次数。通过计算函数表达G(x)求得算法的平均命中率。
DE-Q-Learning算法与对比算法的具体参数见表3。对于其它在实验中所涉及到的参数设定,这里给出统一规定。设定参数“Step”代表各算法在每次探索中所需最大步长,用来限制智能体的移动次数;设定参数“Gen”作为各算法的循环次数,代表最大训练程度。在智能体探索环境时,Q表的每一代变化都为下一代智能体在探索环境时提供了更新信息。
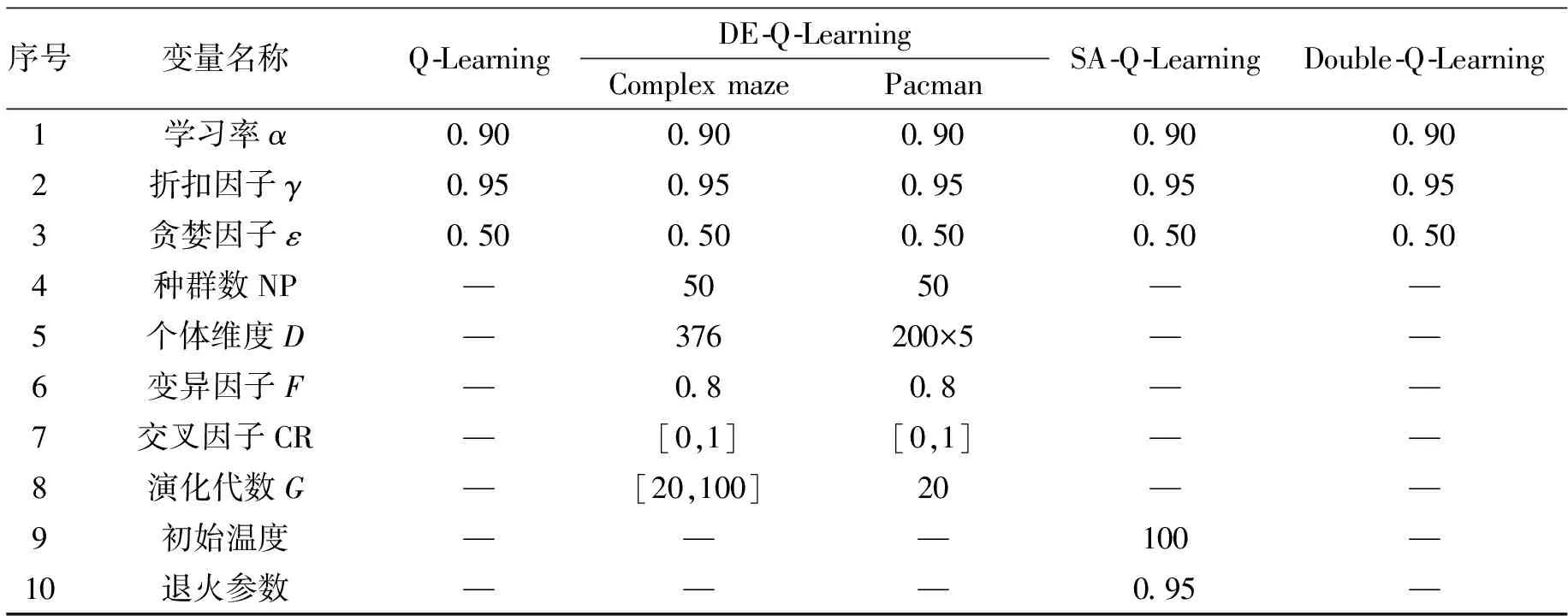
表3 DE-Q-Learning与对比算法参数
3.1.4 实验结果及分析
图9对比了DE-Q-Learning与Q-Learning、Double Q-Learning及SA-Q-Learning算法在目标状态命中率上的比较情况。横坐标表示算法的运行代数Gen,纵坐标为命中率,这里将Gen的取值设为500。图9(a)中,DE-Q-Learning算法在DE处理上的参数设置为:种群数量NP设置为20,演化代数G设置为20。图9(b)中,种群数量NP设置为20,演化代数G设置为50。由实验结果发现,随着演化代数的提升,DE-Q-Learning在命中率上有明显的提升,相较于SA-Q-Learning和Q-Learning,其效果有着明显的提升。而Double Q-Learning在动作选择上采用双估计器的方式来解决过拟合问题,在前期的收敛能力上可能不及Q-Learning和SA-Q-Learning。

图9 DE-Q-Learning在NP为20时与不同算法命中率比较
图10对比了Q-Learning、Double Q-Learning、SA-Q-Learning与DE-Q-Learning在种群个体为50的情况下,分别演化20代与50代的命中率情况。由实验结果可以看出,随着NP数量的增加,算法在空间上提升了搜索效率,在对模型进一步拟合后,得到误差相对较小的最优样本输出,有效地避免了算法进行盲目搜索,更进一步地提高了算法的命中率。
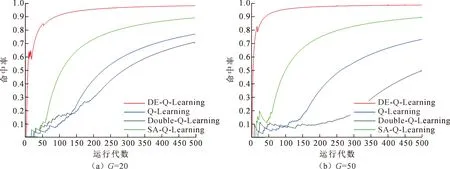
图10 DE-Q-Learning在NP为50时与不同算法命中率比较
图11对比了DE-Q-Learning在NP和Gen都为100代的情况下所得到的命中率曲线。可以观察到,伴随着演化程度的提升,算法在收敛性能上几乎可以做到“零失误”,DE-Q-Learning在效果上远超Q-Learning、Double Q-Learning及SA-Q-Learning。
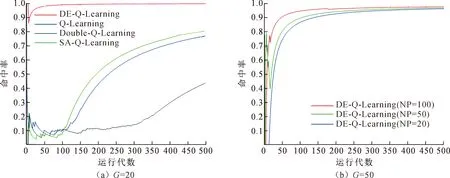
图11 DE-Q-Learning在NP为100时与不同算法命中率比较
图12对比了DE-Q-Learning在NP和G不同取值下的命中率情况。

图12 DE-Q-Learning在NP和G不同取值下的命中率比较
图12(a)绘出了演化种群NP取值为20,演化代数分别为20,50,100时算法的命中率曲线,图12(b)绘制了将演化种群NP提升至50的的命中率曲线。通过实验数据可以看出,在NP不变的情况下,随着演化代数的增加,对算法性能有着明显的提升。而随着种群数量NP的提升,对算法性能也有着一定的改善,但是同时也会带来一定的代价即算法运行时间增加。
从收敛速度上,由于DE-Q-Learning具有独特的隐并行特点,无论从累计回报还是平均回报来看,其算法都具有优异的效果。只有采用时间作为评价标准时,才能满足对比的公平性。在“目标状态命中率”评价标准的基础上,表4分别记录了各算法训练500代所需运行时间。图13为最终的训练效果图,展示了改进算法在路径搜索中所训练出的最佳路径。
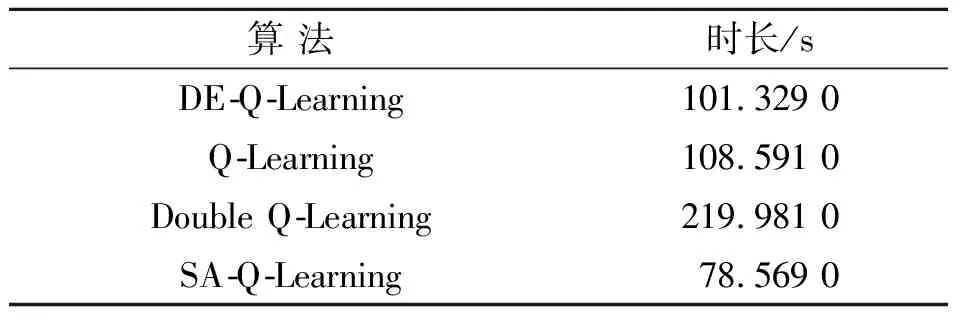
表4 各算法运行500代所消耗时长

图13 训练效果图
3.2 Pacman游戏环境
3.2.1 实验环境参数
Pacman吃豆人游戏是上世纪80年代日本南梦宫游戏公司推出的一款街机游戏,后来被加州大学伯克利分校引入到强化学习的实验环境中作为实操项目,该环境在验证算法的路径搜索能力的基础上添加了动态避障的训练。文中使用该项目中的小型实验环境smallGrid和中型实验环境MediumClassic,如图16~17所示。文中在16GB RAM,512 G硬盘,2.60 GHz 64位处理器,Windows 10操作系统,Python3.7的环境下进行实验。
3.2.2 环境状态设定
在Pacman游戏环境中,强化学习训练的智能体是如图14~15所示的黄色扇形移动体,白色小圆点代表小奖励,白色圆点代表大奖励,具有两只眼睛的椭圆形代表ghost,蓝色边框代表不可穿越的墙体。智能体具有上下左右四个动作维度,状态使用Pacman项目中的layout地图样式表示,可以凸显游戏中各元素的具体位置,pacman碰撞白色小圆点、大圆点分别获取奖励10分和20分,若与ghost碰撞,则会对pacman扣除50分并且游戏结束,并且在游戏中为了避免pacman长时间躲避ghost而不去探索奖励,定义TIME_PENALTY=1作为时间惩罚,即每秒钟pacman会受到-1分的惩罚。训练的目标是智能体pacman通过墙体的保护上下左右移动躲避ghost并且尽可能吃掉所有白色圆点,以期望获得最大的收益。

图14 Pacman-SmallGrid环境
图15 Pacman-mediumClassic环境
3.2.3 适应度函数以及评价指标
Pacman游戏环境利用每回合智能体所得到的回报来判断训练算法的优劣,且智能体的回报根据环境返回观测数据observation得到,全局奖励R随着时间变化如式(12)所示,其中r代表当前状态获得的即时奖励:tp代表时间惩罚值,取值为当前所耗费时间(s)。在DE-Q-Learning算法中Q表个体的适应度值由智能体使用该Q表与环境交互n回合的R取平均得到,其适应度函数为
R=R+r-tp,
(12)
(13)
为了使对比实验结果更加直观,采用每一回合训练得到的R作为评价算法优劣的指标,DE-Q-Learning,算法与对比算法的具体参数见表3。
3.2.4 实验结果及分析
图16展示了DE-Q-Learning算法与对比算法在smallGrid环境中训练2 000代的回报情况,可以观察到文中提出DE-Q-Learning算法在整个训练过程中所得到的回报是高于其他算法的,为了更加直观展现DE-Q-Learning算法的优越性。
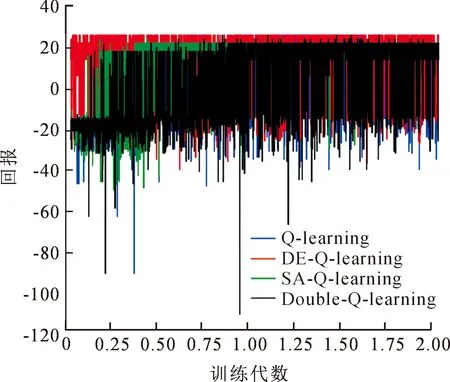
图16 SmallGrid环境各算法训练2 000代回报
图17展示了图16中纵轴的累计回报sum_reward,可以看出与其他算法不同,DE-Q-Learning在训练前期回报远远大于其他算法,并且后期能够快速收敛。在收敛的速度上,表5展示了各算法训练2 000代所消耗的时间,其中Double-Q-Learning算法收敛速度最慢,SA-Q-Learning算法收敛速度最快,其效果也好于原始Q-Learning,DE-Q-Learning收敛速度仅次于SA-Q-Learning。

表5 各算法训练2 000代所消耗时长Tab.5 Time consumed to train each algorithm for 2 000 generations

图17 SmallGrid环境各算法训练2 000代纵轴回报和
式(14)为收敛速度的计算方式,其中Ir(Improvement rate)表示改进算法相对于原始算法速度的提升率,to、ti分别表示原始算法与改进算法训练所耗时长。由表5中各算法训练2 000代的时间数据可知DE-Q-Learning相对于Q-Learning速度提升26.18%,相对于Double-Q-Learning速度提升42.80%,但相对于SA-Q-Learning其速度并无优势;而由表6中各算法训练10 000代的数据可知DE-Q-Learning相对于Q-Learning,Double-Q-Learning,SA-Q-Learning其速度分别提升了28.58%,42.16%,15.88%。

表6 各算法训练10 000代消耗时长Tab.6 Time consumed to train each algorithm for 10 000 generations
(14)
由于mediumClassic环境的复杂程度远远高于smallGrid环境,故训练次数需要大大增加,图18展示了各算法在mediumClassic环境中训练10 000代的回报情况,图19展示了各代累计回报sum_reward,DE-Q-Learning算法在前期、中期、后期的回报仍然远远高于其他Q-Learning改进算法,表6展示了各算法训练10 000代所消耗的时间,DE-Q-Learning算法的收敛速度快于其他改进算法,这说明DE-Q-Learning在复杂的环境中较其他算法更有优势。
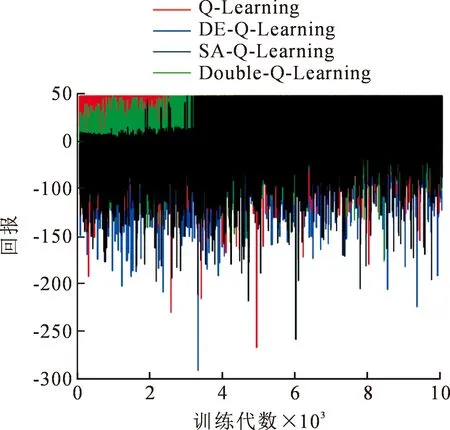
图18 MediumGrid环境各算法训练10 000代回报
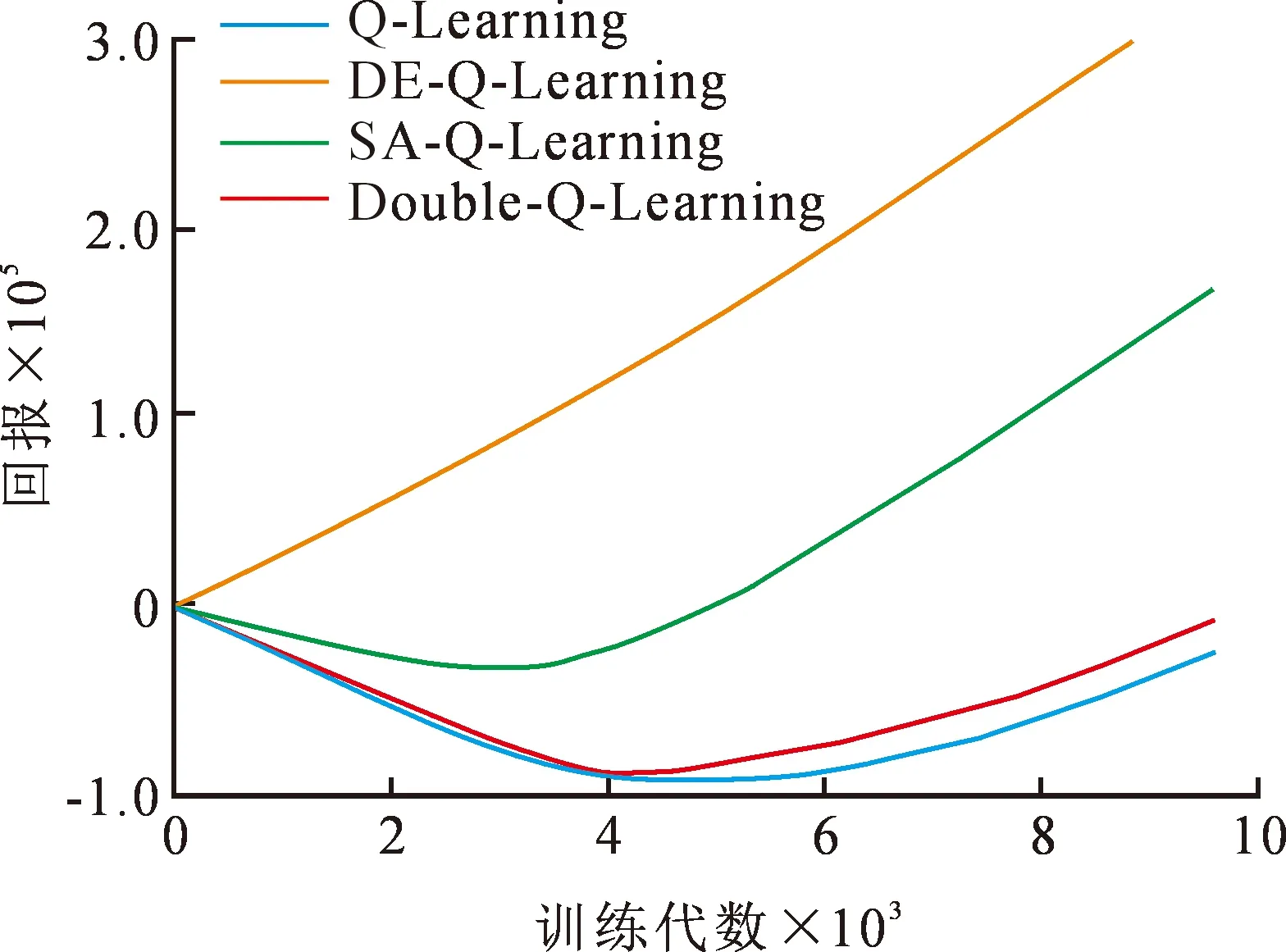
图19 MediumGrid环境各算法训练10 000代纵轴回报
4 结 论
为解决Q表规模增大时Q-Learning前期的盲目搜索问题,文中提出了一种使用演化算法优化Q表的新型算法(DE-Q-Learning)。使用DE算法作为演化算法实例,经过Gym的山地车环境验证后,在复杂迷宫测试环境和Pacman游戏环境中与Q-Learning、Double Q-Learning、SA-Q-Learning三个算法进行比较。实验结果表明,DE-Q-Learning无论在目标状态命中率、累计回报及收敛速度上,都具有优异的表现,算法的性能得到了明显的提升,证明该算法的有效性。从理论上来讲,文中所提出的DE-Q-Learning可以应用于任何Q表有限的无模型问题,具有较好的鲁棒性,并且在演化算法的设定上,不仅局限于DE演化算法,其它的智能算法均可适用于该模型中。但在高维复杂环境中,由于无法创建合适的Q表来存储状态-动作值,且对于一些及时性策略问题Q-Learning算法也无法有效解决,故未来的工作将进一步研究如何利用深度强化学习优化算法解决此类高纬度、及时性的复杂问题。
猜你喜欢
今日农业(2022年15期)2022-09-20
小学生作文(低年级适用)(2019年5期)2019-07-26
红土地(2018年7期)2018-09-26
小学生作文(低年级适用)(2018年3期)2018-04-17
读友·少年文学(清雅版)(2018年12期)2018-04-04
山东青年(2016年3期)2016-02-28
少儿科学周刊·少年版(2015年4期)2015-07-07
当代畜禽养殖业(2014年10期)2014-02-27
中学生物学(2008年6期)2008-08-29
