
基于双源自适应知识蒸馏的轻量化图像分类方法
2023-10-26 06:50张凯兵马东佟孟雅蕾
西安工程大学学报 2023年4期
张凯兵,马东佟,孟雅蕾
(1.西安工程大学 电子信息学院,陕西 西安 710048; 2.西安工程大学 计算机科学学院,陕西 西安 710048)
0 引 言
近年来,随着深度学习技术的迅速发展,计算机视觉领域逐渐得到广泛应用,同时在图像分类[1]和识别技术方面取得了显著进展。然而,大多数有关图像分类的研究都是基于大型深度神经网络或其集合上的,模型有数百万个参数。随着模型参数量的增加,训练过程也需要耗费大量的计算资源,导致训练好的模型难以直接部署到开发板、移动终端以及可穿戴的嵌入式设备上,从而影响深度学习模型的实际应用。知识蒸馏[2]作为一种有效的模型轻量化方法,已经被广泛研究并取得了显著的成果,其成果已应用于各种计算机视觉任务[3-4]。
知识蒸馏指的是将复杂的教师网络的知识传递给一个轻量化的学生网络,从而提高学生网络的泛化能力和性能。根据从教师网络中所获取知识的类型,现有的知识蒸馏方法可以分为以下3类:基于软标签知识的蒸馏方法、基于特征层知识的蒸馏方法和基于结构化知识的蒸馏方法。基于软标签知识的蒸馏方法简单易懂,主要依赖于教师网络最后一层的输出,通过促使学生网络学习教师网络的最终预测,从而达到与教师网络相近或更优的性能。文献[5]最早提出通过一个温度系数对教师网络的输出概率分数进行软化,然后作为软目标来指导学生网络。文献[6]提出了一种教师助教蒸馏方法,首先将助教网络作为学生从教师网络学习软标签知识,然后再指导学生网络的训练。基于特征层知识的蒸馏方法通过对齐教师网络和学生网络中间层的特征,从而使学生网络学习到教师网络特征层的高级语义信息。文献[7]提出通过对齐教师网络和学生网络中间层的注意力特征图来实现知识的迁移;文献[8]提出最小化教师网络和学生网络之间的激活边界差异,从而将知识传递给学生网络;文献[9]分别对教师网络和学生网络的特征进行了空间池化金字塔[10]处理,然后使用L2距离来度量两者之间的距离。基于软标签知识和特征层知识的蒸馏方法都使用教师网络中特定层的输出,而基于结构化知识的蒸馏方法进一步探索不同输入样本之间的关系或者不同层之间的关系等结构化知识。文献[11]提出通过模仿教师网络生成的解决方案流程矩阵来实施对学生网络训练的指导;文献[12]提出将不同样本之间的角度关系和距离关系作为知识,使学生网络学习到教师网络对不同类别样本丰富的结构化知识。
尽管现有的大多数知识蒸馏方法取得了一定的研究进展,但仍然存在一些明显的局限性。一方面,大多数基于特征层知识的蒸馏方法通过最小化教师特征和学生特征之间的距离来传递知识,需要先将教师网络和学生网络的特征变换到同一维度,再进行特征对齐。然而,在特征变换的过程不可避免地会导致信息丢失,同时也增加了计算复杂度。另一方面,基于软标签知识的蒸馏方法通过使用一个带有温度系数的softmax层来软化输出概率分数,然后将其作为训练学生网络的软目标。然而,对所有训练样本使用恒定的温度系数忽略了不同数据样本之间的差异,会限制学生网络对教师网络软标签中有价值信息的学习。
针对以上问题,本文提出了一种新颖的DSAKD方法,从教师网络的特征层和软标签中获取双源类型的知识,从而进一步提高轻量化学生网络的性能。首先,对于教师网络特征层的知识,提出了一个特征自适应融合模块分别将教师网络和学生网络中间层不同尺度的特征融合在一起。然后,为了更好地迁移教师网络的特征层知识,本文提出了一种特征嵌入对比蒸馏策略,将融合后的教师特征和学生特征投影到统一的嵌入子空间[13]中进行知识迁移。最后,对原有的软标签蒸馏方法进行改进,提出了一种自适应温度蒸馏策略,根据教师网络对每个样本的预测置信度为所有样本自适应分配不同的温度系数,从而为学生网络提供更有判别性的软标签。
1 DSAKD方法
本文提出的DSAKD方法通过从教师网络的特征层和软标签中获取多种类型的知识,并通过构造合适的蒸馏损失将知识迁移到学生网络中,从而进一步提高轻量化学生网络的性能。具体来讲,该方法主要由多层特征自适应融合、特征嵌入对比蒸馏和自适应温度蒸馏3个阶段组成,整体框架如图1所示。
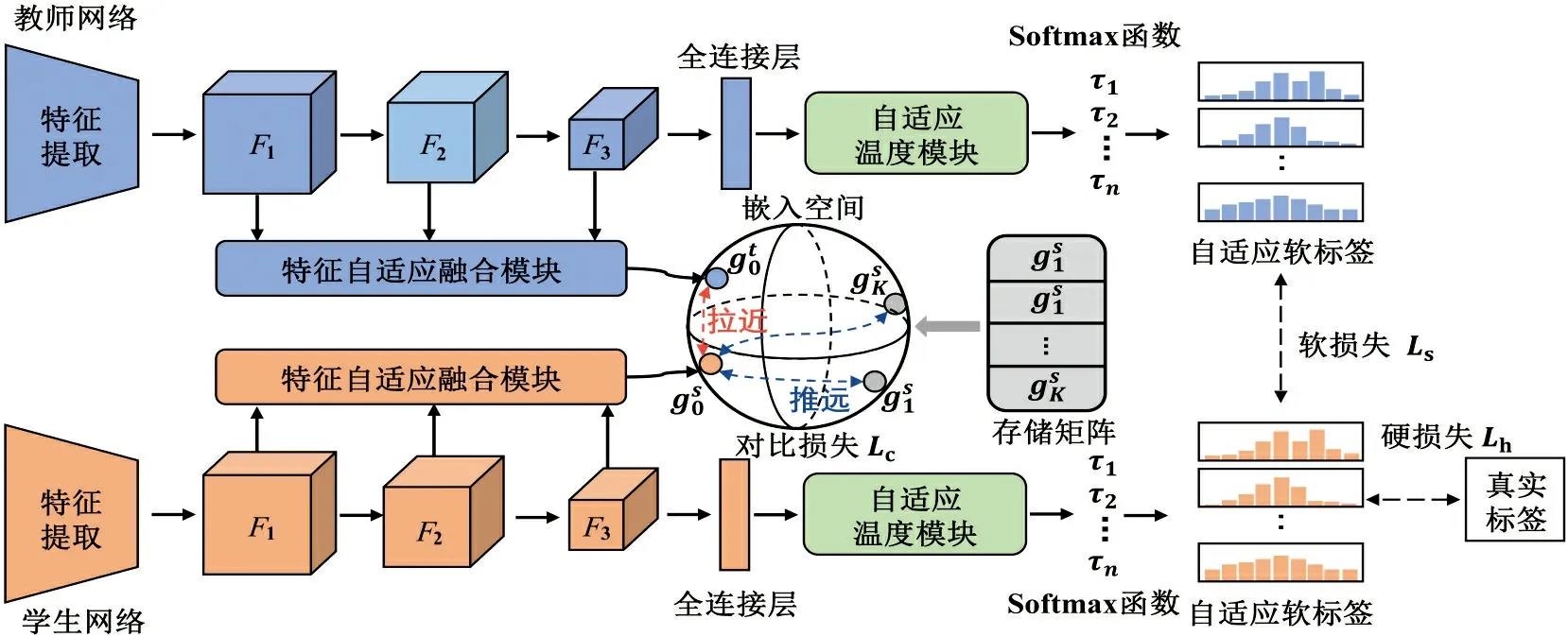
图1 DSAKD方法总体框架Fig.1 Overall framework of DSAKD method
图1中,第一阶段对教师网络和学生网络的多尺度特征进行自适应融合:对于一张训练样本{x0,y0},送入教师网络和学生网络中进行特征提取,分别提取到教师网络和学生网络第k层的特征Fk(k=1,2,3)。然后,将提取到的多尺度特征通过特征自适应融合模块进行自适应融合,从而得到包含更丰富知识的教师特征和学生特征。
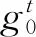
第三阶段主要对教师网络的软标签知识进行学习:通过提出的自适应温度蒸馏策略对每个样本自适应地设置不同的温度参数,进而从教师网络中提取到更有信息量的软标签知识。
1.1 特征自适应融合模块
由于卷积神经网络不同层次的特征旨在编码不同类型的信息,网络浅层学习到的主要是边缘和纹理等低级特征,深层学习到的主要是更加抽象的高级语义特征。为了充分利用网络提取到的低层纹理特征和高层语义特征信息,同时考虑到两者之间的互补性,本文采用图2所示的基于注意力融合的方式对多层特征进行自适应融合[14],得到更有互补性的教师特征对学生网络的特征进行指导。

图2 特征自适应融合模块Fig.2 The illustration of the feature adaptive fusion module
如图2所示,本文提出的特征自适应融合模块主要包含两步:特征图调整和自适应特征融合。将网络中间特征层不同尺度的特征表示为Fk(k=1,2,3)(例如,在ResNet网络中表示每个残差块的输出),由于浅层特征的特征图尺寸大,通道数少,首先采用下采样策略对浅层特征进行调整。对于1/2倍的下采样,使用步长为2的卷积,同时改变浅层特征的特征图尺寸和通道数;对于1/4倍的下采样,在上述操作的基础上,在卷积层之前加入一个步长为2的最大池化层。将调整到同一尺寸的特征进行自适应融合,计算过程可表示为
(1)

1.2 特征嵌入对比蒸馏模块

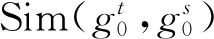

(3)
式中:θ为学生网络的参数;τ为温度系数,控制了模型对负样本的区分度;K为负样本数;M为数据集的训练样本总数。
通过特征嵌入对比蒸馏模块对学生网络进行优化,进一步扩大了教师网络和学生网络之间的类内相似度和类间差异,确保了样本间结构知识的一致性,使学生网络从教师网络的特征层中学习到更有价值的知识,从而获得了性能收益。
如文献[15]所述,为了确保对比学习的性能,需要大量的负样本。而一个正样本对就需要K个负样本,进行(K+1)次的运算,极大地增加了训练负担。为了解决这一问题,本文采用文献[16]的思想,通过构造一个存储体M∈RN×d来存储所有训练样本的d维嵌入特征,只对每次正向传播中的正样本进行更新,从而确保了计算效率。具体来讲,当批大小设置为1时,M的更新遵从下式:
(4)
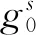
1.3 自适应温度蒸馏模块
在原始知识蒸馏框架中,通过使用一个带有温度系数的softmax函数对教师网络的输出概率分数进行软化,然后将其作为训练学生网络的软目标。此后,这种基于温度的知识蒸馏策略[17]引起了广泛研究者的兴趣并取得了巨大的成功。然而,最近关于解耦知识蒸馏的研究发现,知识蒸馏的性能受训练样本难度的影响。具体来说,文献[18]认为高置信度样本具有大量的有用信息,但这些样本在原有的软标签蒸馏中贡献却很小。因此,本文对原有的软标签蒸馏方法进行改进,提出了一种自适应温度蒸馏策略。
知识蒸馏的思想最早是在文献[5]中提出的,拿一张“猫”图片举例,模型输出它为“狗”的概率比“飞机”的概率要高很多,这些错误的概率包含了不同别之间丰富的知识,并揭示了一个模型倾向于怎样泛化。软标签蒸馏方法通过定义一个温度系数,将大模型的输出logits转化为软化的概率预测分数,来监督小模型的训练,这一过程表示为
(5)
其中:zi和vi分别为教师网络和学生网络的logits;τ为温度系数。
不同于现有的大多数知识蒸馏方法使用一个固定的温度系数(根据经验通常设置为4),本文对原始的软标签蒸馏方法进行改进,提出了一种自适应温度蒸馏方法。具体来讲,针对不同的训练样本,根据教师网络预测的置信度大小,自适应地给所有训练样本分配不同的温度系数。对于那些相对难以识别的样本,当教师网络预测的不确定性高时,给予这些样本较小的温度系数来扩大类间差异;对于那些易于学习的样本,给予它们较大的温度系数从而更有效地利用类间信息。本文提出的自适应温度蒸馏损失如下式所示:
(6)
式中:τi为自适应温度系数。τi的计算公式如下:
τi=τmax-(τmax-τmin)·σ(-∑(φ(zi)·
lnφ(zi)))
(7)
式中:σ(·)为tanh激活函数;φ(·)为softmax函数;通过定义τmax和τmin温度系数τi限制在一个固定范围内。
通过教师网络对每个训练样本预测概率的熵值来衡量对该样本的预测置信度,熵越高说明教师网络对该样本的预测不确定性越高[19],通过式(7)为该样本分配较小的温度系数,从而得到更有判别性的软标签。
1.4 损失函数设计
综上所述,学生网络在特征嵌入对比蒸馏损失、自适应温度蒸馏损失和真实标签损失的联合指导下进行训练,进而从教师网络的特征层和软标签中获取更有价值的知识,训练阶段总的损失函数可以表示为
Ltotal=Lcls+λ·Lcon+μ·Latd
(8)
式中:λ和μ分别为对比蒸馏损失和自适应温度蒸馏损失的权值系数;Lcls为学生网络的分类损失。Lcls的定义如下:
式中:Lce为交叉熵损失;vi为学生网络输出的logits;y为样本的真实标签。
1.5 评价指标
本文实验采用准确率[20](A)对学生网络的分类结果进行评估,计算过程如下:
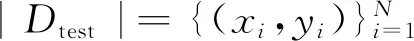
2 实验结果与分析
在本节中,首先对实验所用到的数据集、主干网络和参数设置进行了介绍,然后分别在3个数据集上开展了一系列对比实验来验证本文提出的DSAKD方法的有效性,最后进行了模块的消融实验并对超参数进行了分析。
2.1 数据集介绍
本文在CIFAR10、CIFAR100和ImageNet 3个基准的图像分类数据集上进行实验,通过与其他几种不同的蒸馏算法比较来验证本文所提出的DSAKD方法的有效性。CIFAR10和CIFAR100数据集都是由60 000张32×32大小的彩色图像组成。其中前者包含10个类别,每个类别有6 000张图像;而后者包含100个类别,每个类别有600张图像。CIFAR100数据集由于类别数量更多且每个类别的训练样本数量更少,因此分类难度相对CIFAR10数据集更大。除此之外,考虑到CIFAR10和CIFAR100数据集都是32×32大小的图像,并不能代表自然场景中的图像,本文还在更具有挑战性的ImageNet数据集[21]上进行实验。该数据集共包含128万张训练样本,涵盖了来自1 000个不同类别的物体和场景,每个类别约有1 000个训练样本,并包括50个验证样本和100个测试样本。
2.2 实验设置
本文选择多种不同类型的网络作为主干网络来开展实验,包括:ResNet网络、VGG网络、WideResNet网络以及更轻量化的MobileNet网络和ShuffleNet网络,所有的实验都是在一个深度学习平台RTX 3090 Ti GPU设备上执行,并在Python 3.7编程环境中实现。
在训练过程中,采用一种标准的数据增强[22]方案(包括填充、随机裁剪和水平翻转),对训练集的图像进行均值和标准差的标准化处理。对于CIFAR10和CIFAR100数据集,为了确保对比实验的公平性,采用和文献[23]相同的参数设置:共迭代200个训练轮次,批次大小设置为128,优化器选择随机梯度下降法[24],动量为0.9,权重衰减因子为5.0×10-4,初始学习率为0.1,分别在100、150次迭代下进行0.1倍的衰减。对于ImageNet数据集,共迭代100个训练轮次,批次大小设置为64,优化器同样选择随机梯度下降法SGD,动量为0.9,权重衰减因子为1.0×10-4,初始学习率为0.1,分别在30、60和80次迭代下进行0.1倍的衰减。
2.3 CIFAR100数据集对比实验
课题组在CIFAR100数据集上开展了一系列对比实验来验证DSAKD方法的性能优势,包括同构网络(这里指教师网络和学生网络采用同一类型的网络)的蒸馏对比实验以及更有挑战性的异构网络(这里指教师网络和学生网络采用不同类型的网络)上的蒸馏对比实验。对比方法主要包括:在基于软标签的知识蒸馏方法中性能最好的解耦知识蒸馏Decouple KD[18]方法;在基于特征层的知识蒸馏方法中性能最好的知识回顾Review KD[9]蒸馏方法,以及在基于结构化知识蒸馏方法中性能最好的RKD[12]方法。除此之外,考虑到本文的方法主要是在文献[23]公开的代码上进行改进的,因此将文献[23]提出的对比表征蒸馏方法CRD也作为对比方法之一。所有对比实验的结果均是在作者提供的公开代码的推荐参数配置下实现得到的。
首先,在CIFAR100数据集上进行同构网络对比实验来评估本文所提DSAKD方法的有效性。为了确保对比实验的公平性,本文在4种对比方法都采用的3组网络上开展对比实验。3组同构网络分别为:网络1(ResNet110作为教师网络,ResNet20作为学生网络),网络2(WRN40-2作为教师网络,WRN16-2作为学生网络)和网络3(VGG13作为教师网络,VGG8作为学生网络)。表1展示了在同构网络条件下,本文提出的方法和4种对比方法在CIFAR100数据集上的Top-1验证准确率。图中加粗的字体用于标记最优的准确率,而且所有的实验结果都是重复5次实验取的平均值及标准差。
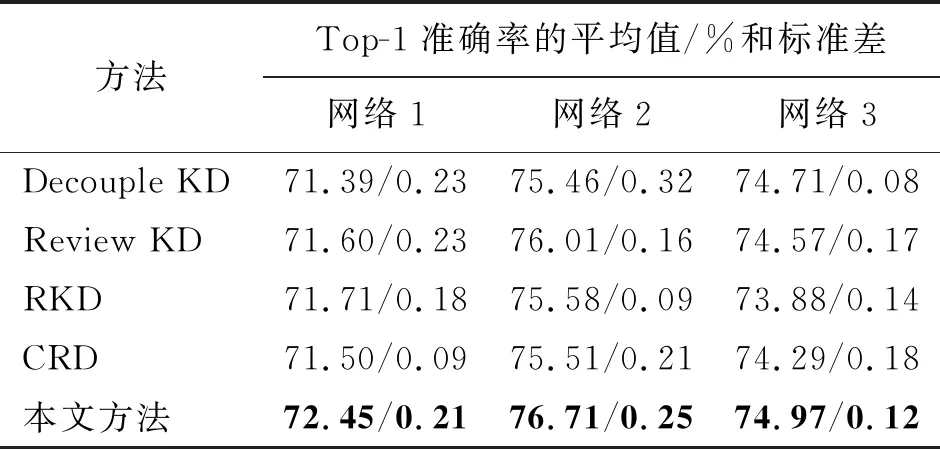
表1 在CIFAR100数据集上的同构网络对比实验Tab.1 The experimental comparison of peer-architecture distillation on the CIFAR100 dataset
从表1可以看出,与其他4种性能优异的蒸馏算法相比,本文提出的方法在3组不同的同构网络蒸馏实验中都获得了最佳的蒸馏性能,显著地提高了学生网络的分类性能。具体来讲,基于软标签蒸馏的Decouple KD主要是从教师网络的软标签中获取知识,经过该方法训练的学生网络虽然获得了性能提升,但是没有考虑到教师网络特征层中丰富的知识。基于结构化蒸馏的RKD方法和基于对比表征蒸馏的CRD都是基于对应层之间进行蒸馏的方法,共同点是让学生网络在训练前期学习复杂的教师知识,导致经过这些方法训练的学生网络提升有限。而Review KD采用一种渐进式融合蒸馏的策略对学生网络的特征层进行知识回顾蒸馏,在4种对比方法中取得了最优的性能。不同于上述4种对比方法,本文提出的方法从教师网络中获取双源类型的知识,并通过提出的特征自适应融合策略、特征嵌入对比蒸馏策略和自适应温度蒸馏策略对学生网络进行优化,使得学生网络能够从教师网络中的特征层和软标签中学习到更丰富的知识。与对比方法中性能最好的方法相比,在3组网络上的平均验证准确率提高了0.57%。
为了进一步证明本文所提出方法的有效性和适用性,本文在更具挑战性的异构网络上进行了对比实验。同样地,选择4种对比方法都采用的3组异构网络进行对比,分别为:网络a(WRN40-2作为教师网络,ShuffleNetV1作为学生网络),网络b(ResNet32×4作为教师网络,ShuffleNetV2作为学生网络)和网络c(VGG13作为教师网络,MobileNetV2作为学生网络)。表2给出了本文方法在3组异构网络上与其他4种蒸馏算法的对比结果。
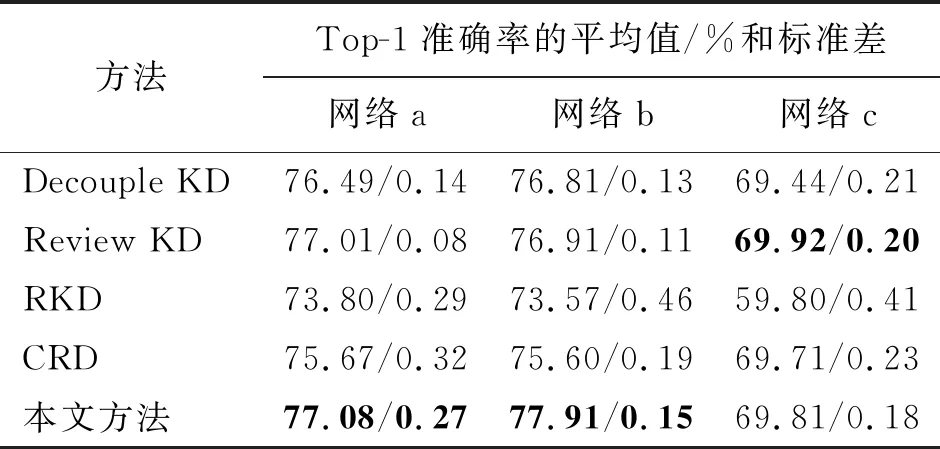
表2 在CIFAR100数据集上的异构网络对比实验Tab.2 The experimental comparison of cross-architecture distillation on the CIFAR100 dataset
从表2可以看出,本文提出的方法在前2组不同的异构网络蒸馏实验中获得了最佳的蒸馏性能,在最后一组异构网络蒸馏实验中获得了次优的性能。总的来说,与对比方法中性能最好的方法相比,在3组网络上的平均验证准确率提高了0.34%。其中,基于结构化蒸馏的RKD方法表现最差,分析原因是异构网络在结构和特征表示上存在较大的差异,这种差异性导致教师网络中的关系信息无法有效地传递给学生网络。基于软标签蒸馏的方法Decouple KD没有考虑到教师网络特征层的知识,效果提升有限。CRD方法没有考虑浅层特征的有效知识,从而在更具挑战性的异构网络上效果较差。然而,本文提出的方法将教师网络的多尺度特征进行自适应融合,并在嵌入空间中通过对比学习进行优化,进一步提高了学生网络的特征提取能力,使得训练的学生网络在异构网络上同样蒸馏效果优异。
为了更直观地展示本文所提方法的有效性,图3展示了经过训练后学生网络和教师网络logits的相关性差异,图中横轴和纵轴分别代表教师网络和学生网络的logits,颜色越深表示两者的差异越大。由于logits是模型输出的前一步骤,相关性的降低表明学生网络更准确地学习到了教师网络的软标签知识。因此,这里选择WRN40-2作为教师网络,WRN16-2作为学生网络,与基于软标签蒸馏的Decouple KD方法进行对比。
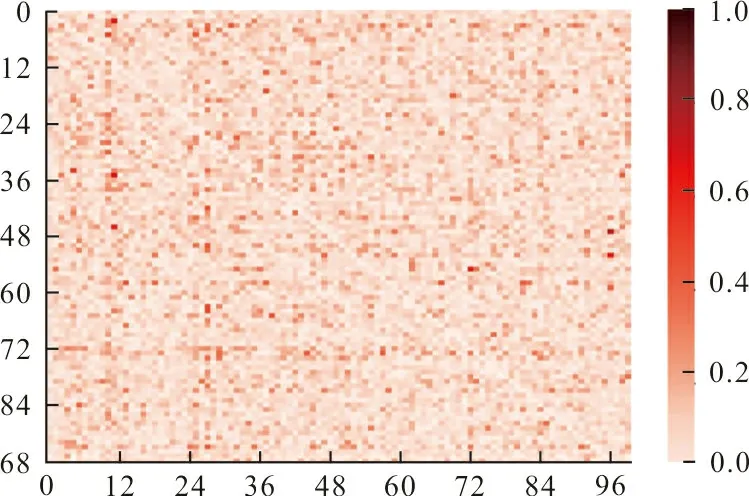
(a) Decouple KD方法
从图3可以看出,经过本文方法训练的学生网络与教师网络的logits相关性差异更小。Decouple KD对所有的训练样本设置同一温度系数来得到样本的软标签,没有考虑不同样本的差异性,从而导致学生网络不能更好地学习和模拟教师网络的预测能力。而本文方法通过为所有的训练样本分配不同的温度系数,减小了数据集中的难分样本和噪声对学生网络的干扰,帮助学生网络从教师网络的特征层和软标签中学习到更具鲁棒性和判别性的知识,有利于进一步减少教师网络和学生网络之间的logits差异,从而提高了学生网络的性能。
2.4 CIFAR10和ImageNet数据集泛化性实验
为了进一步证明本文方法的泛化性能,本文在CIFAR10数据集和更具挑战性的ImageNet数据集上开展了对比实验。表3展示了本文提方法与其他几种蒸馏方法在CIFAR10数据集上取得的Top-1准确率的对比结果,其中对比方法和网络设置与表1相同。
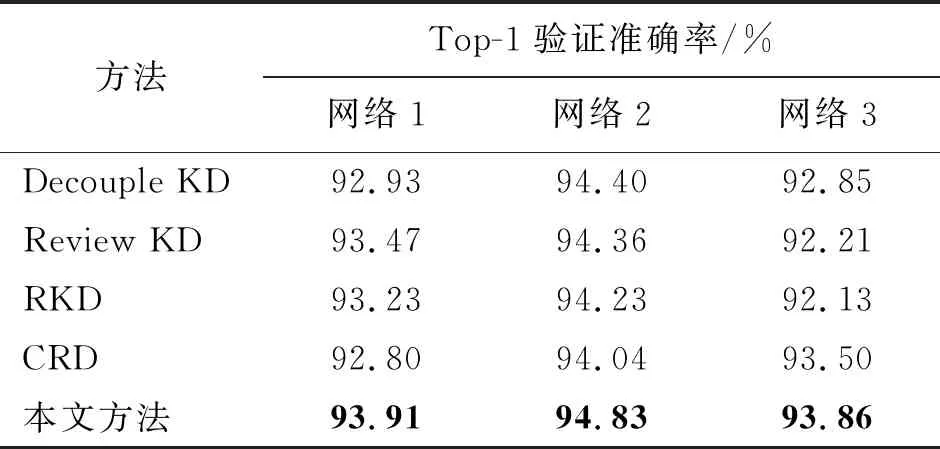
表3 在CIFAR10数据集上的对比实验Tab.3 The experimental comparison on the CIFAR10 dataset
在ImageNet数据集上的Top-1准确率和Top-5准确率对比实验结果如表4所示。对比方法选择基于软标签蒸馏的开山之作Vanilla KD[5]方法,基于特征层蒸馏的注意力蒸馏方法AT[7],基于结构化蒸馏方法中性能最好的RKD[12]方法以及对比表征蒸馏CRD[23]方法。为了确保对比的公平性,本文对4种方法都采用1组网络开展对比实验,选择ResNet50作为教师网络,选择MobileNetV2作为学生网络。
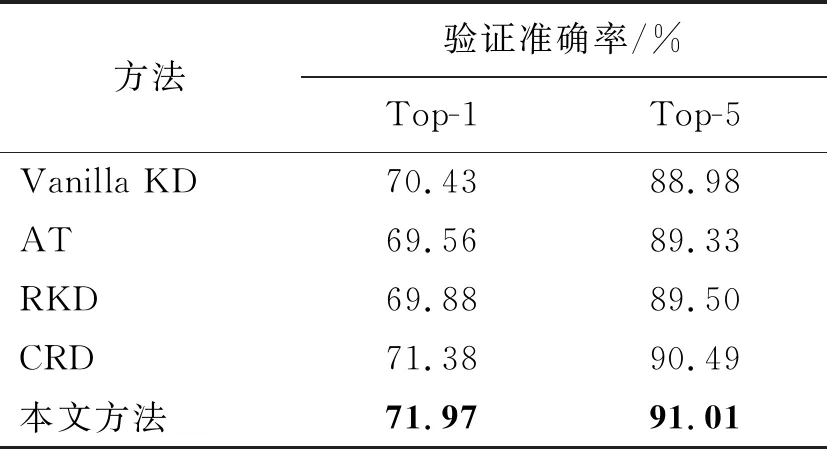
表4 在ImageNet数据集上的对比实验Tab.4 The experimental comparison on the ImageNet dataset
从表3和表4可以看出,本文提出的DSAKD方法在相对简单的CIFAR10数据集和更具挑战性的ImageNet数据集上都取得了优异的蒸馏性能。具体来讲,在CIFAR10数据集上,与对比方法中性能最好的方法相比,在3组网络上的平均验证准确率提高了0.41%。在ImageNet数据集上,与对比方法中性能最优的CRD方法相比,经过DSAKD方法训练的学生网络的Top-1和Top-5识别准确率分别提高了0.59%和0.52%。因此,本文提出的DSAKD方法有着较好的泛化性能,这是因为多层特征自适应融合策略可以帮助学生网络获取更全面的特征表达,而且提出的自适应蒸馏策略针对不同难度的数据集可以自适应设置不同的系数,具有更强的适用性。
2.5 所提模块的消融实验
本文提出的模型包含3个主要模块,即特征自适应融合模块、嵌入特征对比蒸馏模块以及温度自适应蒸馏模块。本文设计了消融实验来进一步验证各个模块的有效性,图4展示了消融实验的结果。
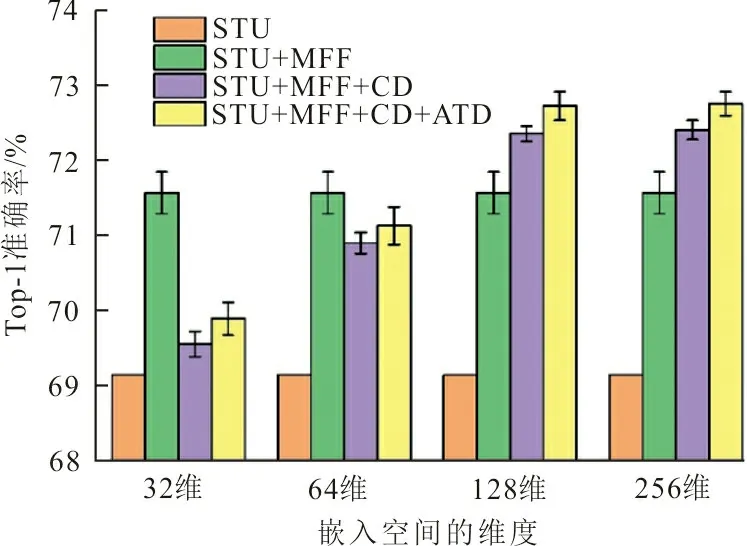
图4 本文提出的3个模块的消融实验Fig.4 The ablation study of the proposed three modules
图4选择ResNet56作为教师网络,ResNet20作为学生网络,不经过任何蒸馏策略训练的学生网络在CIFAR100数据集上的平均验证准确率如橙色柱所示。单独使用多层特征融合策略,将融合后的特征直接进行匹配,实验结果如绿色柱所示。相比于单独使用学生网络进行训练,经过多层特征融合模块训练的学生网络略微提高了学生网络的性能。然后,加入嵌入特征对比蒸馏模块,将融合后的特征投影到嵌入空间中通过对比学习进行优化,结果如紫色柱所示。最后,验证提出的自适应温度蒸馏模块的作用,在紫色柱的基础上增加温度自适应蒸馏模块后学生网络的验证准确率如黄色柱所示。可以看出加入温度自适应蒸馏模块后,网络在原有基础上有了相应的提升。
考虑到嵌入空间的维数对学生网络蒸馏性能的影响,本文在不同维度的嵌入空间进行了对比实验,见图4中横轴所示。考虑到当嵌入空间维度设置过小时,学生网络的性能急剧下降;当维度增加到128后,继续增加学生网络的性能达到了饱和;当维度设置为256时,相比于128维,学生网络的性能几乎没有提升。因此,图4中仅展示了嵌入空间维度从32维到256维的变化。综合考虑计算效率和性能增益,本文选择的最佳的嵌入空间维度为128维。
2.6 参数分析实验
学生网络在特征嵌入对比蒸馏损失、自适应温度蒸馏损失和分类损失的联合指导下进行训练,各项损失间的权值系数对总损失也有影响,因此本文针对权值系数在CIFAR100数据集上对学生网络性能的影响做了实验分析。这里选择WRN40-2作为教师网络,选择WRN16-2作为学生网络,超参数λ和μ对学生网络性能的影响如图5所示。

图5 超参数的参数分析实验Fig.5 The parameter analysis experiment with hyperparameters
从图5可以看出,学生网络的性能容易受到权值系数λ和μ的影响。当λ和μ的取值较小时,所提出的特征嵌入对比蒸馏损失和自适应温度蒸馏损失起的作用也较小,导致学生网络主要在分类损失的约束下训练;当λ和μ的取值逐渐增加时,学生网络的分类性能随之增加,一定程度上验证了本文所提的特征自适应融合模块、特征嵌入对比蒸馏模块和自适应温度蒸馏模块的有效性;当λ取0.8、μ取1.0时,学生网络的性能最优。
3 结 语
本文提出了一种新的双源自适应知识蒸馏方法,从教师网络的特征层和软标签中获取双源类型的知识,从而进一步提高轻量化学生网络的性能。一方面,将教师网络和学生网络的多尺度特征通过特征自适应融合模块进行融合,将融合后包含更丰富知识的特征投影到一个嵌入空间中,通过对比学习的思想对学生网络进行优化,从而提高学生网络的特征提取能力;另一方面,本文对原有的软标签蒸馏方法进行改进,提出了一种温度自适应蒸馏策略,根据教师网络对每个样本的预测置信度为不同的样本设置不同的温度系数,从而将更有判别性的软标签知识蒸馏给学生网络。在3个基准图像分类数据集上的大量对比实验结果表明,本文提出的DSAKD方法在同构网络和异构网络蒸馏上都取得了更好的蒸馏效果,进一步提高了轻量化学生网络的分类性能。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
车迷(2018年11期)2018-08-30
知识经济·中国直销(2018年8期)2018-08-23
海峡姐妹(2018年3期)2018-05-09
数学小灵通·3-4年级(2017年9期)2017-10-13
数学学习与研究(2017年3期)2017-03-09
公民与法治(2016年10期)2016-05-17
中国老区建设(2016年1期)2016-02-28
