
基于YOLOv3 改进算法的烟叶原料烟草甲识别方法研究
2023-12-11 10:02张卫正陈赛越扬王艳玲帖金鑫李灿林苏晓珂
河南农业科学 2023年11期
张卫正,陈赛越扬,王艳玲,帖金鑫,丁 佳,李 萌,李灿林,苏晓珂,甘 勇
(1.郑州轻工业大学 计算机科学与技术学院,河南 郑州 450001;2.浙江中烟工业有限责任公司宁波卷烟厂,浙江 宁波 315040;3.河北中烟有限责任公司,河北 石家庄 050051;4.郑州轻工业大学 烟草科学与工程学院,河南 郑州 450001)
烟草甲(Lasioderma serricorne)是世界性储烟害虫,除了蛀食烟叶造成孔洞,使烟叶成丝率下降,还会产生大量的排泄物及虫尸,严重影响烟叶、成品卷烟质量及品牌形象。为从源头控制烟草甲种群数量,烟叶原料进入加工车间前通常要进行烟虫检测。目前该工序主要为人工识别,由于烟草甲个体较小且体色与烟叶类似,存在工作量大和检测效率低等问题[1]。
近年来,基于深度学习的卷积神经网络(Convolutional neural networks,CNN)凭借优异的特征提取性能弥补了传统图像特征提取方法需要人工设置特征、主观性较强的弊端,被广泛地应用到病虫害检测领域[2-3],越来越多的专家学者将CNN 应用于害虫等小目标的检测[4]。岳有军等[5]提出了改进的VGG 网络来识别复杂自然条件下的农作物病害图像,该模型在VGG 网络的基础上加入了高阶残差和参数共享等模块,改进后的VGG 网络在鲁棒性和识别准确率方面均有所提高。杨光露等[6]设计了一种烟虫检测报警系统,该系统基于CenterNet模型结合数据增强技术实现了烟虫数量的统计,结果显示,烟草甲虫的平均识别精度达到90%以上,但在烟虫粘连情况下,CenterNet 算法无法准确识别烟虫数量。由于烟草甲的隐蔽性高、身形小,且实际采集的图像中常存在烟草甲相互粘连、烟叶与烟草甲颜色相近等影响,极大地增加了检测难度,导致现有的算法大都存在识别精度较低的问题[7]。洪金华等[8]提出了基于YOLOv3 模型的卷烟厂烟虫识别方法,该模型在YOLOv3 算法的基础上加入了数据增强技术和K-means 算法,结果表明,经过训练后改进的YOLOv3模型能够满足卷烟厂对烟虫检测精度和速度的要求,但是对复杂背景下的烟虫检测结果精度较低。张博等[9]对YOLOv3算法进行改进,加入了反卷积结构,并将空间金字塔池化与改进的YOLOv3 相结合,形成了一种基于空间金字塔池化与深度卷积神经网络的作物害虫识别算法,提高了对农作物害虫的识别精度。该算法能够有效地检测20 类害虫,平均识别精度达到88.07%。为克服现有技术在烟草甲相互粘连等情况下检测精度低的问题,提出一种基于YOLOv3 改进算法的烟草甲识别模型,该算法将RandomMix 数据增强和Kmeans++算法加入YOLOv3算法中,提升对烟草甲识别的准确率;用SIoU 损失函数替换传统的YOLOv3算法中使用的IoU 损失函数,提高算法的收敛速度和准确度;引入特征细化模块,有效增强算法在复杂环境下对害虫的精准识别,以期为高效、精确识别烟草甲等小目标害虫提供技术支持。
1 材料和方法
1.1 试验环境
试验基于cuda11.6+pytorch1.12.1 框架搭建烟草甲的识别模型,Python 版本为3.9.13,操作系统为Windows10,GPU为NVIDIA RTX3070。
1.2 数据集制作
1.2.1 图像采集 对附着烟草甲的贮存烟叶进行图像采集,共获取1 200 个图像样本,其中图像大小为1 920 像素×1 080 像素。为了丰富图像样本的多样性,在不同光照强度、烟草甲粘连和复杂背景干扰等环境下采集烟草甲图像,样本图像如图1所示。
1.2.2 数据标注 通过LabelImg图形图像注释工具对图像样本进行标注,将注释以PASCAL VOC 格式保存为XML文件,标注过程如图2所示。

图2 对烟草甲虫图像进行标注Fig.2 Labeled image of cigarette beetles
1.3 YOLOv3网络模型
YOLOv3 是YOLO 系列网络的第3 代,也是最常用的目标检测算法之一[10]。该算法包含主干特征提取网络DarkNet53、特征金字塔网络(Feature pyramid networks,FPN)和Yolo Head 3 个部分[11],网络结构如图3 所示。该算法属于one-stage 目标检测算法,只需要通过一次网络模型检测就能得到目标的位置和种类信息,大大提升了算法的预测速度。
DarkNet53 主要是由3×3 和1×1 的卷积层构成,每个卷积层之后都加上一个BN 层和leaky Relu 激活函数,这3个结构共同组成了DarkNet的基本卷积单元DBL,DarkNet53 中一共有53 个这样的DBL。DarkNet53 还具有一个重要特点就是使用了5 个残差块[12],每个残差块输入经过2 层的DBL 后与原输入比较,能够有效提取更深层次的特征,并且能够防止梯度消失和梯度爆炸的情况。从DarkNet53 中获取3个有效特征层后,为了进一步提取特征,用特征金字塔网络进行特征融合,其目的是结合不同尺度的特征信息。利用融合后的3个不同尺寸的特征层输入到Yolo Head 中得到预测结果,可以获得边界框的高度和宽度以及中心点坐标。Yolo Head 是由一个3×3 卷积和一个1×1 卷积组成,其中3×3 卷积是用来整合不同尺寸的特征,1×1 卷积用来调整通道数。
1.4 改进的YOLOv3网络模型
1.4.1 重新聚类锚框 YOLOv3 本身是用K-means
算法聚类出锚框的,但K-means 算法的聚类结果易受初始值选取影响[13]。因此,选用K-means++算法对锚框进行重新聚类,基于数据集中待检测物体的尺寸计算出锚框的大小,更加适合对烟草甲数据集的检测[14]。用K-means++算法重新聚类锚框的算法流程如下。
步骤1:从数据集中随机选择1 个样本x作为第1个聚类的中心,记为c1。
步骤2:计算当前已有聚类中心与数据集中每个样本x之间的最短距离,用D(x)表示最短距离。
步骤3:计算数据集中任意样本x成为聚类中心的概率P,如公式(1)所示[14]。
步骤4:结合轮盘法选定下一个聚类中心c2。
步骤5:重复步骤2到步骤4,直到一共有K个聚类中心被选定。
步骤6:分别计算数据集中每个样本x到所有K个聚类中心之间的距离,并将其与距离最小的聚类中心分到同一个簇中。
步骤7:重新计算每个簇的聚类中心ci,如公式(2)所示[14]。
步骤8:重复步骤6 和步骤7 直到聚类中心的位置不再变化。
步骤9:输出结果。
1.4.2 RandomMix 数据增强 通常情况下在训练过程中的样本数量越多,训练出来的深度学习网络模型效果越好,模型的泛化能力和鲁棒性越强[15]。本研究采用RandomMix 数据增强的方法,将烟草甲的图像样本扩充到2 200张,为改进的YOLOv3网络训练提供了充足的有效样本。
Mixup[16]是近几年提出来的一种混合样本的数据增强方法,它的核心思想是采用线性插值的方式从训练集生成新的数据点与标签的随机凸组合(Convex combinations),将2 个样本-标签数据对按比例相加后生成新的样本-标签数据。在Mixup中,混合操作如公式(3)所示。
其中,(xA,yA)和(xB,yB)是2 个训练样本,(x͂,y͂)是生成的训练样本,混合比λ是从beta 分布中采样的,λ的取值为λ~Beta(α,α),其中α∈(0,∞)。结合Mixup 和Cutout的思想,CutMix[17]提出了一种新的数据增强策略,其中在训练图像之间剪切和粘贴块,并且GT 标签也与块区域按比例混合,如公式(4)所示。
其中,M表示二进制矩形掩码,指示从2个样本中退出和填充的位置,1 是填充有1 的二进制掩码,表示元素乘积,混合比λ从均匀分布中采样,λ的取值为λ~U(0,1)。
ResizeMix[18]通过直接将源图像调整为更小的块,随后将其粘贴到另一张图像上来混合训练数据,解决了CutMix 中标签分配错误和对象信息丢失的问题。对于Fmix[19],它使用通过对从傅里叶空间采样的低频图像应用阈值获得的随机二进制掩码,从而进一步改善CutMix 混合区域的形状。RandomMix 的主要功能是通过整合这些方法来提高模型的鲁棒性并增加训练数据的多样性。此外,RandomMix 可以减少对错误标签的记忆,并能够稳定生成对抗网络的训练过程,实现更好的性能。RandomMix 方法的流程图如图4 所示,其中的重影现象是Mixup增强后的显示效果。
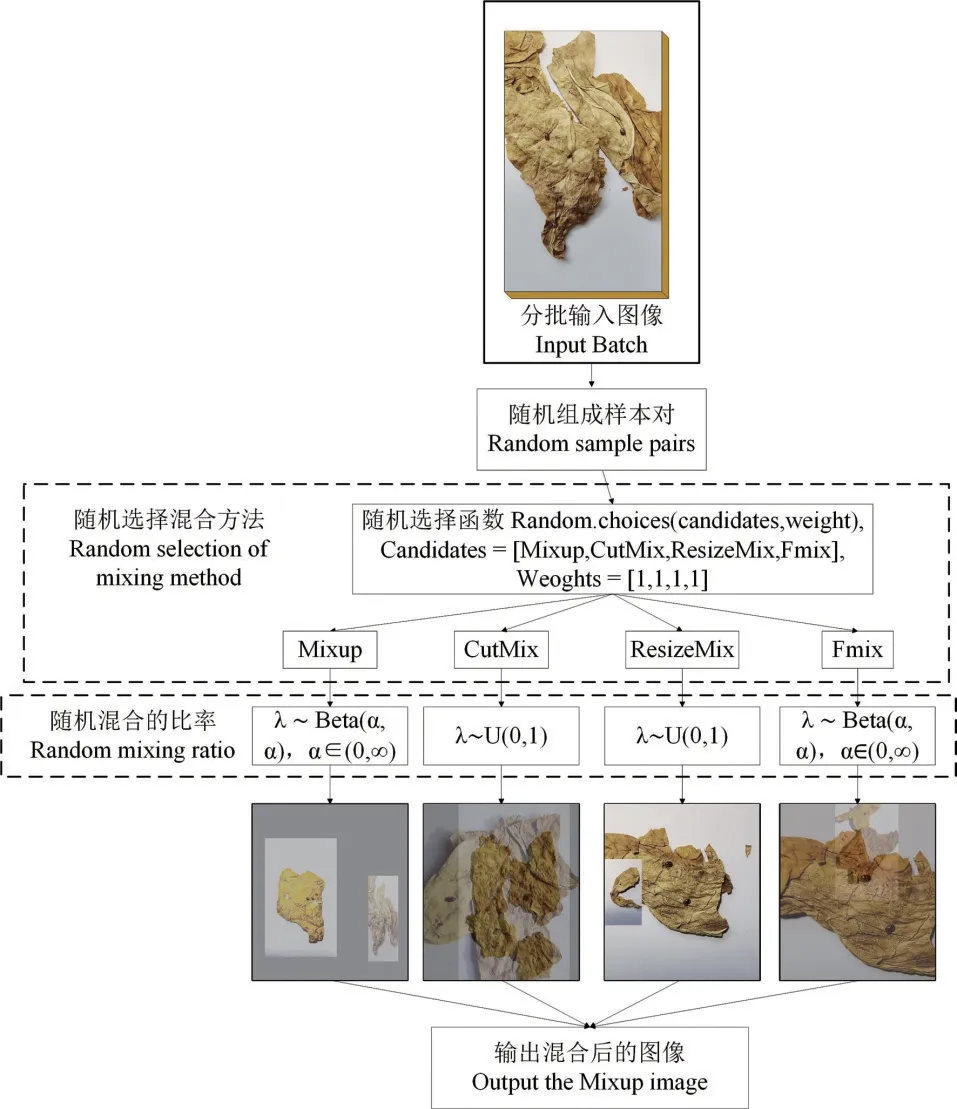
图4 RandomMix方法流程Fig.4 An illustrative example of RandomMix
首先,对输入的Batch 进行随机样本配对,接下来为了获得更多样化的混合样本,将配对好的样本从候选样本中随机选择一种混合方法来混合配对样本。随机选择混合方法的定义为从[Mixup,CutMix,ResizeMix,Fmix]中,按照[1,1,1,1]的概率随机选择方法。最后,使用混合样本来训练模型。利用Random Mix 数据增强得到的烟草图像如图5所示。

图5 数据增强获取的烟草甲虫图像Fig.5 Cigarette beetles images acquired by data enhancement
1.4.3 SIoU 损失函数 目标检测算法的准确性和有效性高度依赖于损失函数的定义,损失函数由边界框损失函数、置信度损失函数和分类损失函数三部分组成[20]。在传统的YOLOv3 算法中使用并交比(Intersection over Union,IoU)作为边界框损失函数来判断样本的正负,其计算方法如公式(5)[20]所示。
其中,B表示预测候选框,Bgt表示真实框,∩表示2个框相交的面积,∪表示2个框的并集的面积。
当2个边界框之间没有重叠时,梯度回传消失,此时计算的IoU 为0,2 个边界框之间的距离无法计算;且IoU无法区分2个对象之间的对齐方式[21]。为了解决该问题,本研究提出用SIoU Loss 作为YOLOv3 算法的边界损失函数,考虑真实框和预测框之间的向量角度,重新定义相关损失函数,能够更好地优化边界框的具体位置信息。SIoU 包含角度损失(Angle cost)、距离损失(Distance cost)、形状损失(Shape cost)、IoU损失(IoU cost)四部分。
第1 部分是角度损失,其计算方式的示意图如图6 所示。其中,B是目标框,BGT是回归框,当B到BGT的水平夹角小于45°时,向最小α 收敛,反之向β收敛。
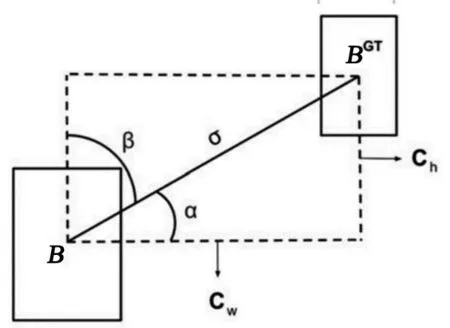
图6 角度损失计算方式示意Fig.6 Angle cost calculation mode diagram
实现该功能的损失函数定义如公式(6)所示。
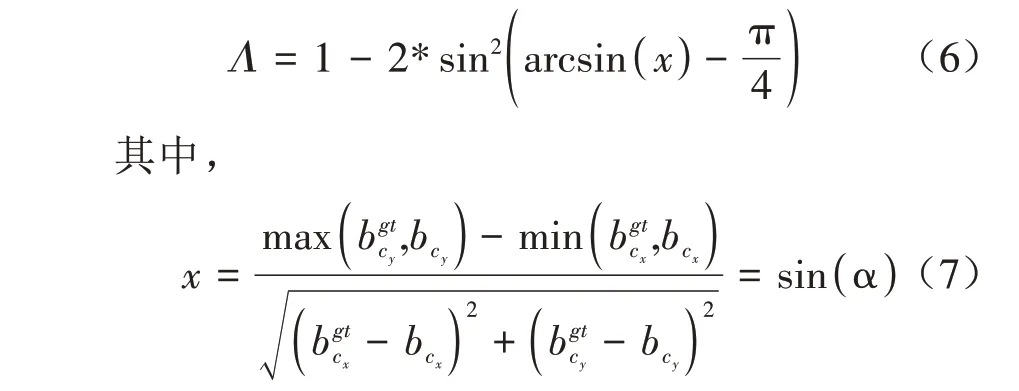
从图6 可以看出,当α 为0 或π/2 时,角度损失为0。在训练过程中,若α<π/4,则在角度损失公式中需要取β值来计算角度损失,反之则取α值。
第2 部分是距离损失,为了保证距离与角度的平衡,需要在考虑角度损失的同时考虑到距离损失,距离损失的定义如公式(8)所示。
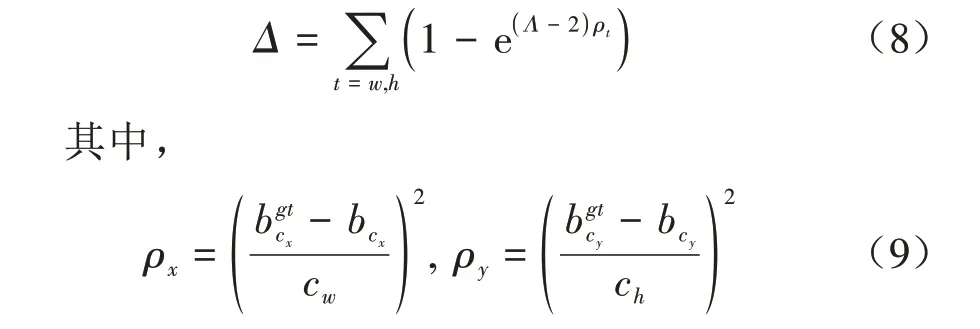
可以看出,当α→0 时,距离损失的占比大大降低。相反,α 越接近π/4,距离损失占比越大。即随着角度的增大,距离损失的影响也更大。
第3部分是形状损失,其定义为:

从定义来看,形状损失主要看回归框的形状与标签框是否相似,在每个数据集中形状损失的值是唯一。θ值控制着形状损失的重要程度。本研究中试验定义的θ值是4。
最后一个是IoU 损失,结合前三部分得到总体的损失函数定义如公式(12)所示。
1.4.4 特征细化模块 YOLOv3 中的FPN 模块作用是将各种规模的特征进行融合,但是直接将特征进行融合会因为不同规模的特征之间的语义差异带来大量的冗余信息和冲突信息,特征的多尺度表达能力会因此下降。因此,为了解决微小物体的特征分散和语义差异的问题,本研究将特征细化模块[22](FRM)加入YOLOv3 的FPN 模块中,目的是过滤冲突信息,减少语义差异,通过自适应融合不同层间的特征,消除层间的冲突信息,防止小目标消失在冲突信息中。FRM的整体结构如图7所示。
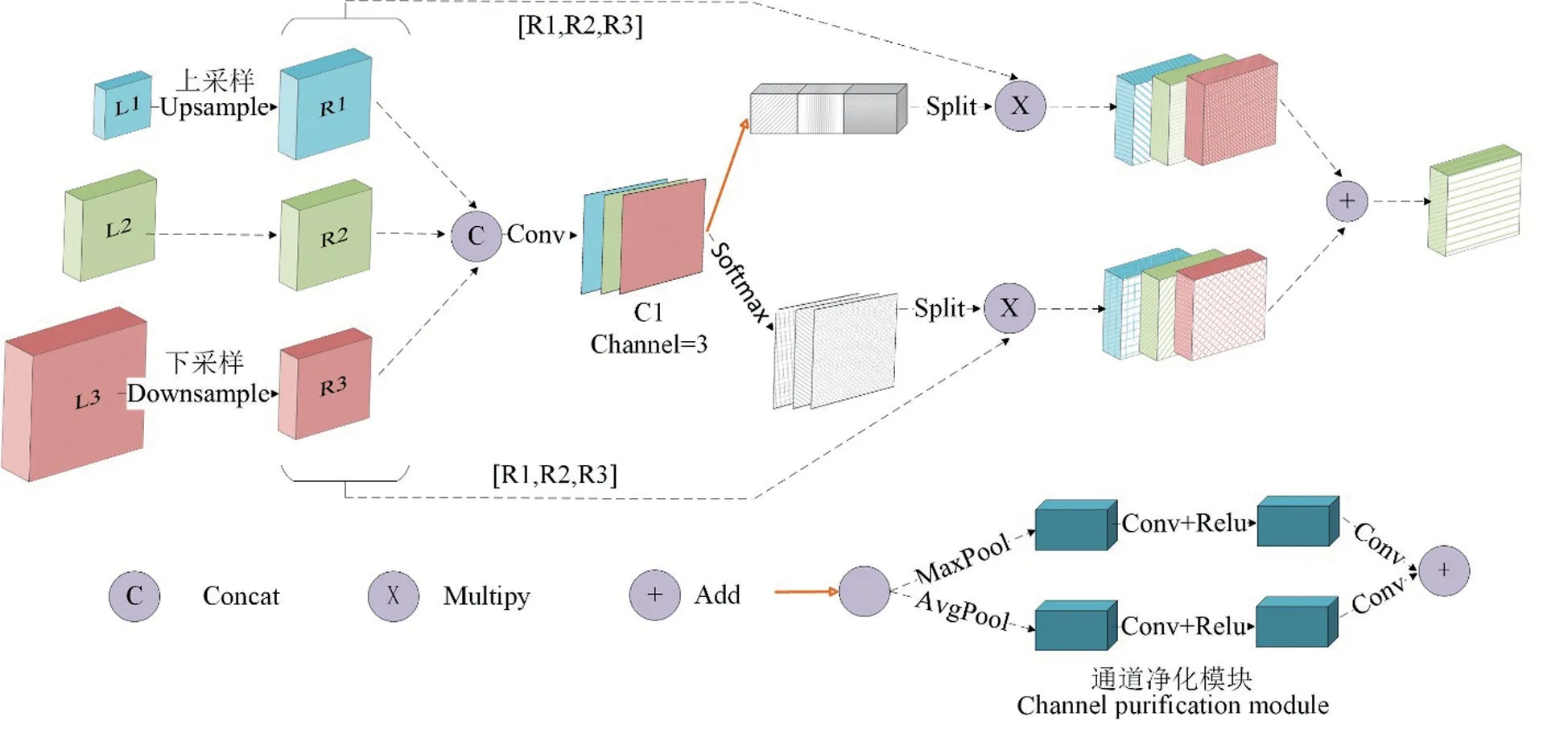
图7 FRM结构Fig.7 The framework of FRM
从图7 可以看出,FRM 主要由2 个并行分支结构组成,即通道净化模块和空间净化模块[22]。它们用于在空间和通道维度上生成自适应权重,从而引导特征向更关键的方向学习。通道净化模块的结构如图7 所示。为了获得通道注意图,在空间维度上对输入特征图进行压缩,以聚集能够代表图像全局特征的空间信息。自适应平均池和自适应最大池相结合,以获得更精细的图像全局特征。Xm被定义为在FRM 的第m层(m={1,2,3})的输入。xmk,x,y被定义为位置(x,y)处第k个通道上第m个特征映射的值。因此,上面分支的输出如公式(13)所示[23]。
式中,a、b和c是通道自适应权重,定义为由图7中的串联操作生成的特征计算它的平均池化和最大池化,再在空间维度上对这2个权重求和,最后利用sigmoid 激活函数生成基于通道的自适应权重a、b和c。
空间净化模块通过sofmax 生成相对于通道的所有位置的相对权重,下分支的输出定义如公式(14)所示[23]。

FRM的总输出可以表示为[23]:
最后FPN 的所有层的特征在自适应权重的指导下被融合在一起,并且{P1,P2,P3}被用作整个网络的最终输出。
1.5 评价指标
为了验证改进的YOLOv3模型对烟草甲虫目标检测的准确性,采用精确率(Precision)、召回率(Recall)、F1 分数(F1-score,F1)、平均精度均值(Mean average precision,mAP)、每秒帧率(Frame per second,FPS)作为评价指标来评估所提出的方法。精确率是指在被所有预测为正的样本中实际为正样本的概率;召回率指在实际为正的样本中被预测为正样本的概率,F1分数同时考虑精确率和召回率,让两者同时达到最高,取得平衡。计算公式如下:
式中,TP表示正确预测出来的正样本数量,FP表示将负样本错误预测为正样本的数量,FN表示将正样本错误预测为负样本的数量。
平均精度均值指的是各类别平均正确率的平均值,计算出所有类别的平均正确率后除以类别总数即得到平均精度均值,计算公式如公式(19)所示:
其中,ΣAP表示全部类别的平均精度值之和,N(C)表示全部类别的总数。mAP的值越高,模型的检测效果就越好。
2 结果与分析
2.1 参数设置与训练
经过Random Mix数据增强后得到2 200张经过标注的烟草甲虫图像,从中随机选取的训练集、测试集和验证集的图像数量分别为1 800、200、200张。在训练模型时,初始学习率设置为0.001,总训练轮次(Epoch)大小为100,为了不破坏已有的参数状态并加快训练速度,将主干特征提取网络冻结一部分[24]。本试验设置前30 轮训练为冻结训练,且训练批次(batch_size)设置为6,随后将其解冻并将学习率设置为0.000 1,训练批次设置为3,训练到100轮次。
根据改进的YOLOv3 模型和原YOLOv3 模型提供的训练日志,可以表征模型的损失函数值随训练轮次变化的曲线,如图8 所示。可以看出,2 种模型均在前期快速收敛,但随着训练轮次增加,改进的YOLOv3 模型的损失值比原YOLOv3 模型的损失值更低。最终改进的YOLOv3 模型的损失值稳定在3.1 左右,而原YOLOv3 模型的损失值为9.8,表明改进的YOLOv3模型的精确度更高。
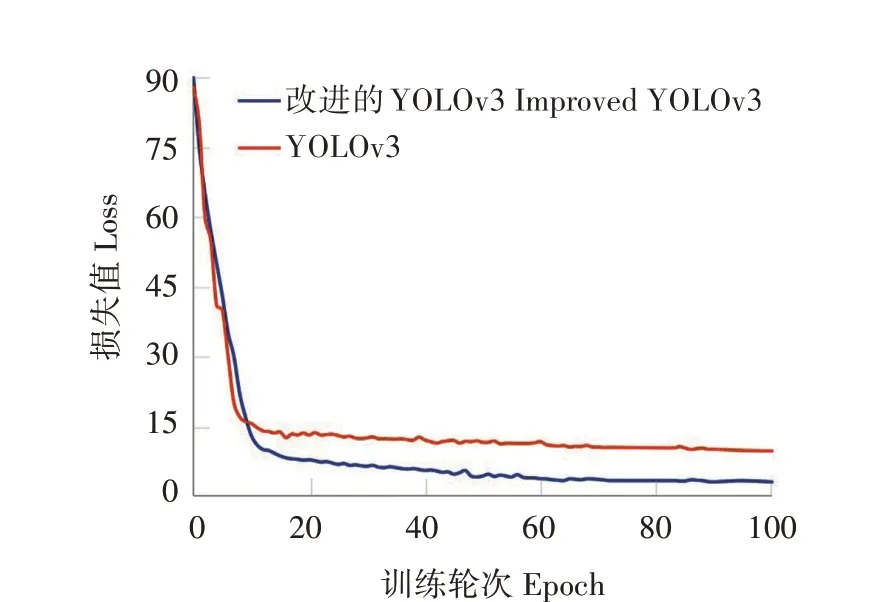
图8 模型损失值曲线Fig.8 Curve of model loss value
2.2 不同模型的检测结果比较
利用训练完成后的改进的YOLOv3模型对烟草甲虫图像进行识别,得到的预测效果如图9所示。

图9 改进的YOLOv3预测可视化结果Fig.9 The prediction visualization results of improved YOLOv3
从预测结果可以看出,改进的YOLOv3 模型可以精准定位烟草甲所在区域并用预测框标识,在图像中显示害虫类别和置信度。为了验证改进的YOLOv3 模型的有效性,分别采用YOLOv3 模型和改进的YOLOv3 模型识别多个烟草甲的图像,部分检测结果如图10所示。

图10 YOLOv3与改进的YOLOv3预测结果对比Fig.10 Comparison of YOLOv3 with improved YOLOv3
YOLOv3 模型在图像清晰度不高时识别烟草甲可能会出现漏检的情况,而改进的YOLOv3 模型可以克服这种情况。结合多张图像的预测结果对比分析可得,和原YOLOv3 模型相比,改进的YOLOv3模型对复杂环境下的烟草甲具有更好的识别效果。
将改进的YOLOv3 模型与YOLOv3、Faster RCNN、YOLOv4、YOLOv4-tiny、YOLOv5、SSD(Single Shot MultiBox Detector)、Retinanet 等模型进行比较。对上述模型均采用相同的硬件设施和相同的数据集进行训练,8 种模型在相同的烟草甲数据集上的精确率、召回率、F1分数、mAP值和每秒帧率结果如表1所示。
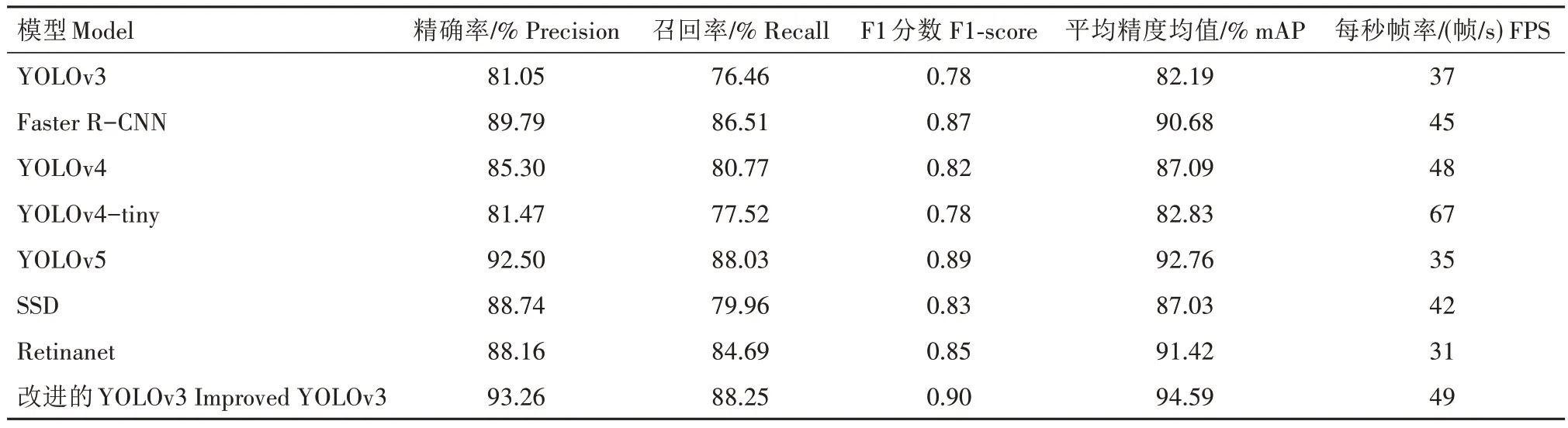
表1 不同模型的检测结果Tab.1 Test results of different models
从表1 可以看出,改进的YOLOv3 模型比YOLOv3 模型的精确率、召回率、F1 分数、mAP 值和每秒帧率分别提高了12.21 百分点、11.79 百分点、0.12、12.40 百分点和12 帧/s,具有更好的识别精度和识别速率,可以更快更好地完成烟草甲虫的实时检测工作。虽然YOLOv5模型在精确率、召回率、F1分数和mAP 上都很接近改进的YOLOv3 模型,YOLOv5 模型在识别精度方面只是稍微落后于改进的YOLOv3模型,但是其每秒帧率只有35帧/s,可见YOLOv5 模型的识别速率较低,并不能满足烟草甲虫实时检测的要求。Faster R-CNN、YOLOv4和SSD模型都能够较为快速地完成烟草甲的识别任务,但是它们的精确率、召回率、F1 分数和mAP 都明显低于改进的YOLOv3 模型,表明改进的YOLOv3 的识别精确度比起其他算法具有较为明显的优势。虽然在每秒帧率上YOLOv4-tiny 模型比改进的YOLOv3 模型具有优势,但是其他指标与改进的YOLOv3 模型相比均较低且有明显差异,并且改进的YOLOv3 模型在每秒帧率上达到49 帧/s,已满足烟草甲虫检测的识别速度要求。
综上所述,与其他检测模型相比较,改进的YOLOv3 模型兼顾精准和高效的要求,对烟草甲虫的识别效果最好,拥有更为强大的泛化能力,能够满足对复杂环境下的烟草甲虫进行准确且高效地识别的任务,并且对开发复杂背景下的小目标识别系统有很好的应用价值。
3 结论与讨论
本研究在对烟草害虫识别领域进行分析后,针对该领域目前存在的问题,提出了基于改进的YOLOv3 算法的贮存烟叶中的烟草甲识别方法。该方法在YOLOv3 算法的基础上做出了如下创新:①用K-means++算法重新聚类锚框,大大提高了YOLOv3 算法识别烟草甲的精准率;②引入RandomMix 数据增强,扩充样本数据集数量并提高样本数据集的质量;③使用SIoU 边界回归损失函数替代IoU 回归损失函数,提高模型定位的准确性,加速模型收敛;④在YOLOv3 的特征金字塔模块(FPN)中加入特征细化模块(FRM)来过滤冲突信息,防止微小目标特征被淹没在冲突信息中,优化复杂背景下的小目标识别。利用建立的烟草甲虫数据集进行训练和测试,结果表明,改进的YOLOv3模型比原YOLOv3 模型的损失值更低、识别精度更高,针对复杂环境下烟草甲的识别更准确。改进后的模型在烟草甲识别精确率、召回率、F1 分数和mAP 上 分 别 达 到 了93.26%、88.25%、0.90 和94.59%,通过与Faster R-CNN 和SSD 等7 种目标检测算法相比,各项数值都有明显提升,显示了改进后算法的准确性和有效性。改进后算法的检测速度为49 帧/s,能够满足烟草甲的实时检测需求。该算法在检测速度方面还有提升的空间,后续将在保证算法准确性的基础上提高算法检测速度。
本研究通过收集贮存烟叶中的烟草甲图像,采用改进的YOLOv3 模型对烟草甲数据集进行测试,取得了较好的识别效果。虽然目前YOLO算法已经发展到了YOLOv8,但是本研究所提出的改进的YOLOv3 模型在烟草甲检测的实时性、准确性和易用性等方面仍具有独特优势。YOLOv4 相对于YOLOv3 需要更高的计算资源要求,对于一些配置较低的硬件设备,运行效率较低,对GPU 显存的要求也会更高。尽管YOLOv4在目标检测性能上有所提升,但由于引入了更多的计算复杂度,它的推理速度相对较慢。而YOLOv3在速度和实时性上表现较好,更适用于烟草甲害虫的实时检测,能够做出更加快速的响应。YOLOv5 模型采用了轻量级的网络架构,以实现更快的推理速度,但这会导致一定的精度损失。而YOLOv3则平衡了计算资源与性能之间的关系,通过引入多个不同尺度的特征图和预测层,可以适应复杂背景下的烟草甲检测任务。在多尺度目标检测方面,YOLOv3 引入了多尺度预测和特征融合机制,可以捕捉目标的细节和上下文信息,推断目标的位置和类别,从而更好地解决检测时部分烟草甲之间存在遮挡与重叠的问题。YOLOv6 模型的代码不够完善,缺乏严谨的解释,并且在检测精度与速度上都不能满足实时检测烟草甲的需求。在模型大小方面,YOLOv7 和YOLOv8模型包含更多的卷积层和参数,需要更多的计算资源和时间来训练和推理,增加了计算机硬件和时间的成本,而YOLOv3 则可以在相对更短的时间内完成训练。在检测精度方面,与YOLOv8算法相比,改进的YOLOv3算法在烟草甲这一小目标的检测上的精度更高、速度更快,能够满足实时检测烟草甲的需求。本研究通过一系列优化模型和增强数据集等措施改进了YOLOv3 模型,相比于其他YOLO 算法,在烟草甲的实时检测方面具有更高的速度和更好的适用性,能够在实时性、准确性和易用性等方面取得较好的平衡。
猜你喜欢
奥秘(创新大赛)(2023年3期)2023-05-06
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
浙江中西医结合杂志(2017年2期)2017-01-12
当代化工研究(2016年9期)2016-03-20
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
电子设计工程(2015年6期)2015-02-27
