
基于集成学习的松辽盆地砂岩型铀矿地层岩性自动识别研究
2023-12-26 01:23段忠义杨亚新罗齐彬
原子能科学技术 2023年12期
段忠义,肖 昆,*,杨亚新,黄 笑,姜 山,张 华,罗齐彬
(1.东华理工大学 核资源与环境国家重点实验室,江西 南昌 330013;2.核工业二四三大队,内蒙古 赤峰 024000)
北方沉积盆地砂岩型铀矿作为我国储量最多的铀矿类型,区内仍有大面积的铀异常亟待查证,铀矿资源勘探潜力巨大[1]。在铀矿勘查中,地球物理测井数据作为连接地球物理性质变化和地下地质环境的桥梁,是了解地下岩层结构和储层特征的有效且不可替代的方法。因此,测井数据解释在铀矿勘查中具有重要意义[2-3]。对测井数据的分析和挖掘已成为提高勘查效率的重点之一[4-7]。随着测井勘探技术的发展,在地下地质结构环境多变且复杂的情况下,对测井数据的解释和地层分析也提出了更高的要求[8-11]。利用测井数据的分析结果对地下空间目标进行准确的识别与划分是测井资料解释的重要环节,包括地层结构划分、沉积相、岩性识别、以及储层识别等[12-13]。其中岩性识别在理解地质体结构、成矿信息预测等研究中发挥着重要作用[14-15];储层识别是复杂储层勘探开发的基础,储层的正确表征是降低勘探开发风险的重要手段,可为更好地设计和制定方案提供依据。
岩性识别是测井数据分析的核心,目前广泛使用的岩性识别方法主要有:传统岩性识别方法,包括交会图法[16-18]、概率统计方法[19-20]、聚类分析方法[21-23];机器学习类岩性识别方法,包括支持向量机SVM[24-26]、神经网络[27-28]、集成学习类方法[29]。传统的岩性识别、储层识别方法存在精度、识别效率和泛化能力低等问题[30]。针对异常值、不平衡性和高复杂性的测井数据,传统的测井解释方法有很大的局限性。随着储层地质条件的复杂性以及测井数据的多样性和数量不断增加,主观的专业知识和经验无法更好地解释。在面对复杂且更具挑战性问题时,机器学习类方法为实现自动化、性能提升提供了新的解决方案,在大量数据中学习复杂的模式和关系方面显示出巨大的优势,使得岩性识别、储层识别有了新的突破[31-33]。
集成学习是通过融合两个或多个模型的显著属性在预测中达成共识的方法,使得最终的学习框架较单个构成模型更全面,减少了误差和其他因素影响。相对于普通机器学习算法,集成学习算法在数据处理方面有更多优势,面对复杂度较高的问题,可以增强分类性能的信息融合,以获取更可靠的决策。基于Boosting的XGBoost模型借助由回归树组成的强学习器,引入了正则项与并行计算技术,在提高效率的同时,确保了模型的可靠性[34];基于Bagging优化的SMOTE随机森林算法借助人工合成少数过采样技术,解决了数据样本的不平衡问题[35]。因此,本文采用集成学习算法中的XGBoost和SMOTE随机森林模型开展砂岩型铀矿地层岩性识别研究,对松辽盆地的砂岩型铀矿建立岩性自动识别模型,以模型岩性识别的准确率为评价标准,并与KNN模型和GBDT模型进行对比分析,考察改进集成模型的可行性,以提升我国北方砂岩型铀矿储层识别的效率与精度,为实现我国铀矿资源勘查战略性突破提供技术支撑。
1 理论与方法
1.1 XGBoost算法
在Friedman[36]提出的Boosting算法基础上,Chen等[37]通过改进目标函数与优化导数信息,并针对性地处理缺失值和模型过拟合,提出了一种优于GBDT的模型,即XGBoost模型。相较于GBDT,XGBoost精度更高、灵活性更强,并行计算与列抽样的引入提高了XGBoost的计算效率。
XGBoost的目标函数如下:
(1)
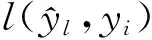
经过t次迭代得到目标函数:
(2)
对式(2)进行二阶泰勒展开:
(3)
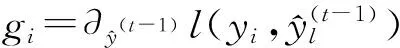
(4)
1.2 基于SMOTE的随机森林算法
随机森林算法属于集成算法中的Bagging方法,作为一种集成学习方法,它在随机选择的数据样本上构建了许多决策树。然后从每棵树上获得预测,并通过多数投票,选择获得多数票的决定。其中构建随机森林算法模型的步骤如下:1) 从给定数据或训练集中随机挑选K个数据点作为随机样本;2) 构建与K个数据点相关联的决策树;3) 选择要构建的树的数量,定义为N,然后重复前两步;4) 对于一个新数据点,让已经构建的N棵树来预测新数据点所属的类别,并将新数据点分配给赢得多数票的类别。
对于处理高维数据的分类问题,随机森林表现出不错的效果,通过Bagging算法弥补了单个决策树对训练集噪声的敏感问题,降低了训练多棵决策树存在的关联问题,有效解决了模型过拟合问题。
针对数据集中出现的分类不平衡问题,采用SMOTE合成少数过采样技术,在保持样本各自形态的基础上进行插值,使各类数据平衡,以此提高少数类的分类精度[38-39],在SMOTE合成邻近样本示意图中,横纵坐标通常代表数据点的某些特征。假设一个二维数据集的每个数据点都有两个特征组成:特征1和特征2。这种情况下,示意图的横坐标通常代表特征1,纵坐标则代表特征2。具体过程如图1所示。
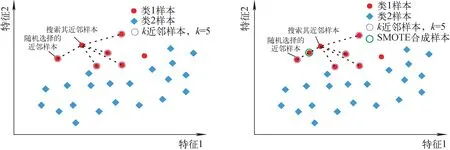
图1 SMOTE合成邻近样本(据Chawla等[39])Fig.1 SMOTE composite adjacent sample (modified from Chawla et al[39])
2 建模与应用
本文以我国北方松辽盆地典型砂岩型铀矿区为研究对象,砂岩型铀矿地球物理测井资料为基础数据,提取研究区目的井次2 860个数据点作为训练数据集,1 270个数据点作为验证数据集。
2.1 样本构建
根据岩石粒级的粗细程度与综合测井曲线对岩性进行划分,依次为黏土、泥岩、粉砂岩、细砂岩、中砂岩、粗砂岩和砂砾岩。以多维数据为样本进行训练,划分岩性作为样本的可靠分类标签,结合砂岩型铀矿中不同岩性在不同地球物理测井数据中的响应规律,进行测井属性的优选,挑选在砂岩型铀矿岩性研究中常见的测井曲线作为输入变量:井径(CAL)、岩石密度(DEN)、声波时差(DT)、放射性(γ)、自然伽马(GR)、三侧向电阻率(LLD3)、视电阻率(RT)、自然电位(SP)共8条曲线[40],每种岩性的不同测井曲线幅值差异如表1所列。
由表1可知,岩石的致密程度与各物性参数存在一定的相关性,如密度和视电阻率随岩石粒级的增加呈增长趋势,声波时差则相反;自然伽马数值相对较高,但在中砂岩中存在局部高自然伽马值,表明研究区含矿主岩为砂岩。对于同岩性的岩石,其数值变化范围较大。泥岩一般放射性伽马值相对较高,砂岩放射性伽马值相对较低。但从粉砂岩、细砂岩以及中砂岩的自然伽马值来看,出现了部分高自然伽马值,指示一定的铀矿异常或矿化特征。
为了进一步分析岩性类别在测井变量组合之间的区分度,通过交会图分析测井响应参数对岩性储层的敏感性,结果如图2所示。
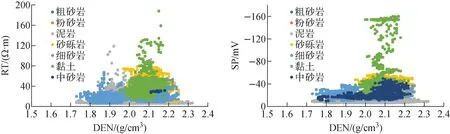
图2 二维测井参数交会图Fig.2 Cross plot of two-dimensional logging parameters

a——密度校深曲线;b——视电阻率校深曲线图3 曲线校深图Fig.3 Corrected depth chart
由图2可看出,在二维测井交会图中,岩性样本点的分布越离散,对岩性的区分度越好。黏土较其他3种岩性分区明显,其密度相对较高,聚集程度较高,而粉砂岩、中砂岩、细砂岩与粗砂岩重叠在一起,不易分类。总体来看,二维测井曲线交会图不能很好地划分砂岩型铀矿岩性,故需要采用分类功能更全面的集成学习法来进行精确岩性划分。
2.2 数据处理
1) 曲线校深与曲线滤波
测井过程中,受地下地质环境客观因素以及操作方法等影响,测井响应值在深度上存在不一致性,不能有效完成后续处理解释工作。本文采用CIF Log2.1测井软件中的数据预处理模块对工区原始测井数据进行校深和滤波,使同一口井中所有测井数据之间的深度关系保持一致,以满足后续测井资料处理与训练要求,具体过程如图3所示。滤波采用10点移动平均滤波以过滤序列中的高频扰动,保留有用低频趋势。
2) 标准化
在利用集成算法进行岩性识别时,不同类型的测井曲线具有不同的量纲和数量级,其差异性会对模型的识别精度产生影响[41]。本文采用Scikit-learn中的StandardScaler模块对数据的特征维度进行去均值和方差归一化,使数据符合正态分布,转化函数如下:
(5)
其中:μ为所有样本的均值;σ为所有样本数据的标准差。
2.3 模型应用与对比
1) 模型参数设置
对于由XGBoost模型建立的岩性识别模型,可以根据其高度的灵活性优势,自定义优化目标和评价标准,在参数调优过程中,除通用参数和学习目标函数外,对模型预测结果影响较大的参数是学习率(learning_rate)和树的最大深度(max_depth)。
在初始化模型参数时,尽量让模型的复杂度较高,然后通过网格搜索GridSearchCV超参数空间调优来降低模型复杂度。学习率和最大迭代次数这两个参数的调优是联系在一起的,学习率越大,达到相同性能的模型所需要的最大迭代次数越小;学习率越小,达到相同性能的模型所需要的最大迭代次数越大。XGBoost每个参数的更新都需要进行多次迭代,因此,学习率和最大迭代次数是首先需要考虑的参数,且学习率和最大迭代参数的重点不是提高模型的分类准确率,而是提高模型的泛化能力。因此,当模型的分类准确率很高时,最后一步应减小学习率的是调节树的最大深度,以提高模型的泛化能力,逐步降低模型复杂度。调参过程如图4所示,其中,纵坐标为数损失函数(Log Loss),用于衡量模型对真实标签的概率预测与实际标签之间的差异,较小的学习率通常需要在模型中添加更多的树,可以通过调整参数组合来探索这种决策关系;横坐标表示树的最大深度,从5~40不等;学习率从0.1~0.5不等,max_depth有8个变量,learning_rate有5个变量。每个组合使用10倍交叉验证进行评估,因此共需要训练和评估400个XGBoost模型。调参目标是针对给定的学习率,使性能随树的数量的增加而提高,然后稳定下来。由于算法或评估过程的随机性或数值精度的差异,结果可能会有所不同,需要多次运行并比较平均结果,多次迭代后将输出每个评估的最佳组合以及对数损失函数。最终可以得到最佳结果的学习率为0.2,树的最大深度为10。
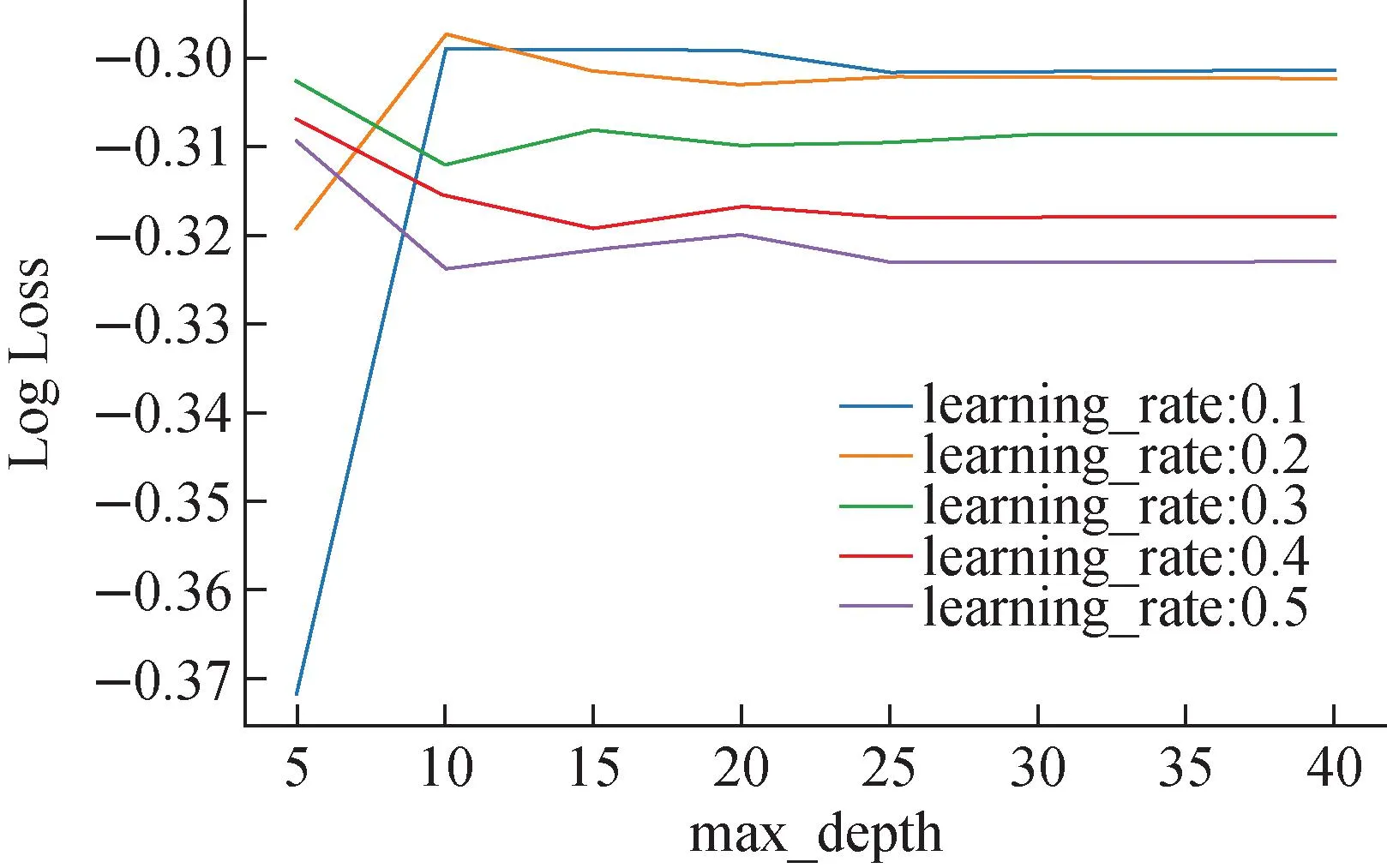
图4 学习率和树最大深度的变化Fig.4 Learning_rate and max_depth tendency chart
在构建提升树之后,检索每个属性的重要性分数。通常,重要性分数反映的是每个特征在构建模型内的增强决策树中的有用性或价值。使用决策树做出关键决策的属性越多,其相对重要性就越高,为数据集中的每个属性明确计算此重要性,允许对属性进行排名和相互比较。单个决策树的重要性是通过每个属性分割点改进性能度量的量计算的,由节点负责的观察数加权。性能度量可以是用于选择分割点的纯度(Gini指数)也可以是另一个更具体的误差函数。对于集成模型中的多棵决策树,可以计算每个决策树的特征重要性,并对所有决策树的特征重要性取平均值,以此更全面地评估特征的重要性。
使用的内置XGBoost特征重要性图,因算法或评估程序的随机性或数值精度的差异而有所不同,因此多次运行该示例,并比较平均结果,如图5所示,其中横坐标F score表示每个特征的重要性得分,衡量的是特征在模型中的相对重要程度;纵坐标Features表示测井特征参数。从图5可知,重要性相对较高的特征参数为CAL和DEN。
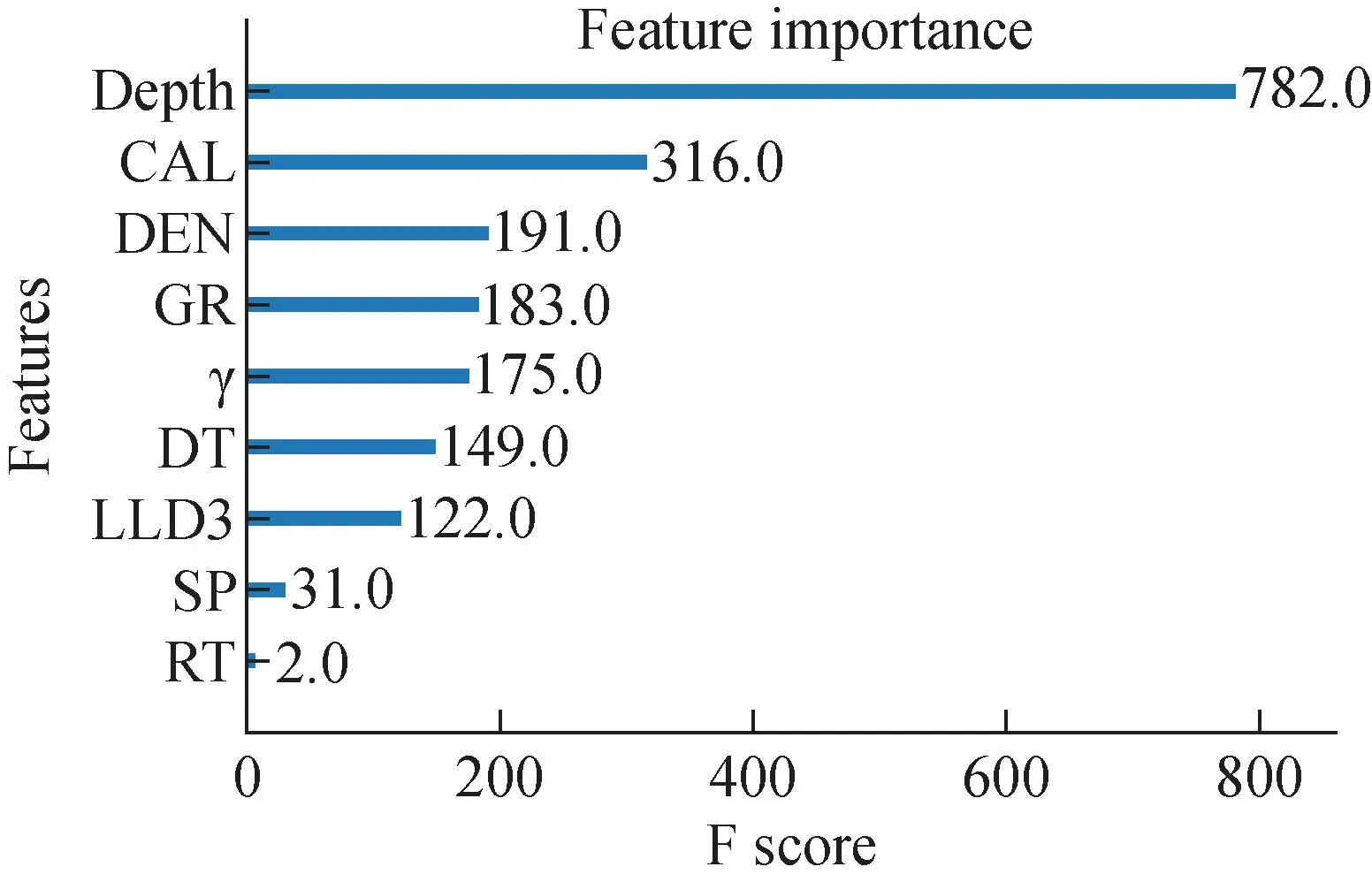
图5 XGBoost特征重要性筛选Fig.5 XGBoost feature importance screening
2) 模型预测结果及与真实结果的对比
经过模型参数调整和交叉验证后,两种模型样本测试集中的岩性分类结果如图6所示,其中横坐标为岩性:1,粗砂岩;2,粉砂岩;3,泥岩;4,砂砾岩;5,细砂岩;6,黏土;7,中砂岩。用混淆矩阵分析模型的分类结果,按照真实类别与模型预测类别两个标准进行统计,最终以矩阵形式呈现。其中矩阵的行表示真实值,矩阵的列表示预测值。

图6 混淆矩阵预测数据Fig.6 Confusion matrix prediction data
上述混淆矩阵的每个单元格(i,j)表示模型将真实类别为i的样本预测为类别j的数量,观测值在对角线位置,数值越多越好;反之,在其他位置出现的观测值则越少越好。对于7种岩性,两种集成模型都表现出较好的识别效果,其中泥岩和细砂岩的分类结果与其他岩性的差异明显,XGBoost模型略优于SMOTE随机森林模型。
受试者工作特征(ROC)曲线是模型的另一种评价指标,ROC曲线下与坐标轴围成的面积(AUC)用于衡量分类模型的准确性。ROC曲线反映的是不同阈值下真正例率和假正例率之间的权衡关系。在ROC曲线中,完美测试的AUC值为1,表示模型在所有阈值下都能完美区分正例和反例。对角线表示随机猜测的模型性能,即真正例率等于假正例率。利用所计算的AUC值,可以衡量分类器在不同阈值下的整体性能,面积越大,表示模型的分类准确性越高。ROC曲线越接近左上角,说明模型在预测样本为正样本的同时还尽可能地减少了错误分类。采用XGBoost模型和SMOTE随机森林模型所得ROC曲线如图7所示。由图7可知,两个模型的ROC曲线都靠近左上角的点,且AUC值均大于0.7,说明两种模型都具有较高的诊断价值,最佳边界点是曲线最靠近左上角的点,其中XGBoost模型最佳边界点的敏感度为0.8,特异度为0.25。SMOTE随机森林模型最佳边界点的敏感度为0.6,特异度为0.26。可见XGBoost模型较SMOTE随机森林模型诊断价值更高,整体预测结果更优。
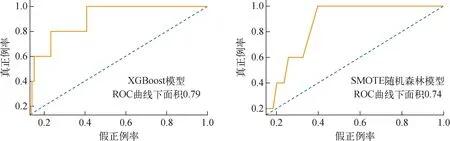
图7 ROC曲线Fig.7 ROC curve
为了检验本文所建立的集成模型的准确性,将XGBoost模型与SMOTE随机森林模型的识别结果与KNN模型和GBDT模型的识别结果进行对比。利用CIFLog2.1测井软件绘制部分井段钻井取心的岩性剖面与模型预测剖面,如图8所示。从图8可知,XGBoost模型和SMOTE随机森林模型能更准确地对地层不同岩性做出响应,与钻井取心的岩性剖面的对比可知,XGBoost模型和SMOTE随机森林模型对于砂岩型铀矿岩性的识别较其他模型更准确。针对岩性连续变化的井段,XGBoost模型的岩性识别效果与钻井取心岩性剖面基本一致,SMOTE随机森林模型的岩性识别效果与钻井取心岩性剖面绝大部分对应较好,但对于少部分数据集较少的井段会出现岩性不对应的情况,这是因为随机森林算法对于小数据或低维数据(特征较少的数据),不能达到很好的分类效果。而KNN模型和GBDT模型在面对高维数据和不平衡数据时所表现出的局限性,导致部分岩性不能准确对应,识别效果与XGBoost模型和SMOTE随机森林模型相比较差。各模型的运行时间和准确性如表2所列。
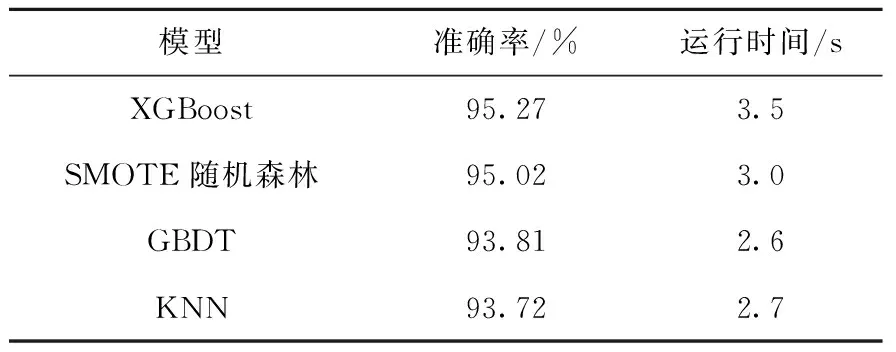
表2 各模型的准确率和运行时间Table2 Accuracy and running time of each model
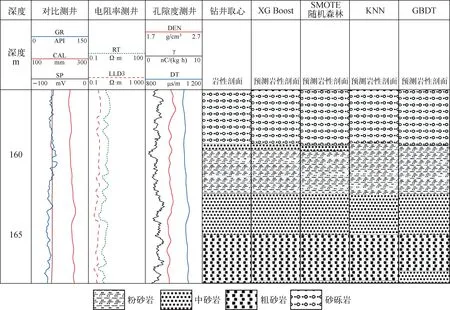
图8 单井段岩性识别效果Fig.8 Single well interval lithology identification result
由表2可知:XGBoost模型的识别效果最好,准确率高达95.27%,其次是SMOTE随机森林模型,准确率为95.02%;GBDT模型和KNN模型的分类效果较弱,准确率分别为93.81%和93.72%。XGBoost模型之所以准确率最高,在于XGBoost模型采用并行计算技术使得多个弱分类器组合进行学习,模型学习的结果优于以决策树作为基学习器的GBDT模型,同时还借鉴了随机森林的列抽样,降低过拟合。从运行时间来看,基于模型本身的原理简单,模型训练较快来考虑,KNN模型和GBDT模型所用时间较短。整体上,XGBoost模型和SMOTE随机森林模型优于KNN模型和GBDT模型,这是因为集成学习通过不同方法改变原始训练样本的分布构建分类器,最终集合弱分类器成强分类器,并且在每轮迭代中使用内置交叉验证,方便获得最优迭代次数,减少了计算量,提高了模型准确率。其中Boosting方法每次迭代时训练集的选择与前面各轮的学习结果有关,而且每次通过更新各样本权重的方式来改变数据分布;Bagging方法每次迭代前,采用有放回的随机抽样来获取训练数据,这使得每次迭代不依赖之前建立的模型,生成的各弱模型之间没有关联,可以彻底实现训练数据之间的并行训练。
3 结论
1) 通过测井资料和交会图分析,确定了与模型相关的8条曲线作为输入变量,并运用模型评价指标对两种集成学习模型进行评估,验证了模型的可行性;利用网格搜索GridSearchCV从超参数空间寻找最优的参数组合,运用10倍交叉验证结合参数组合,通过迭代确定了初步最优化模型。
2) XGBoost模型对损失函数添加正则项以及二阶泰勒展开,弥补了传统Boosting算法的缺陷,提升了优化效果,通过对缺失值切分方法的优化,使得每个特征的缺失值学习到一个最优的切分方向,特征的正确排序与分割结合多线程并行极大提高了运算准确率。
3) Boosting和Bagging两种集成学习在预测分类中都表现出不错的性能,XGBoost模型对砂岩型铀矿地层岩性识别的准确率最高,达到了95.27%,SMOTE随机森林模型次之,KNN模型的识别效果最差。
猜你喜欢
云南化工(2020年11期)2021-01-14
矿产勘查(2020年9期)2020-12-25
四川地质学报(2020年3期)2020-05-22
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
世界核地质科学(2018年2期)2018-07-05
世界核地质科学(2018年2期)2018-07-05
录井工程(2017年1期)2017-07-31
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
