
融合时间上下文与长短期偏好的序列推荐模型
2022-10-24 02:39胡胜利
湖北民族大学学报(自然科学版) 2022年3期
胡胜利,林 凯
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
序列推荐系统的主要目标是挖掘用户交互序列中的关系模式[1].最先应用于序列推荐的是Rendle等[2]提出的个性化马尔科夫链分解模型(factorizing personalized markov chains,FPMC),模型通过矩阵分解和转移矩阵对用户的长期偏好和动态转移进行建模.随着深度学习技术的飞速发展[3],已出现多种基于该技术的序列推荐模型.Hidasi等[4]提出了基于循环神经网络(recurrent neural network,RNN)的序列推荐模型.随后Hidasi等[5]在其原有模型基础上引入了项目属性信息,并将门控循环单元引入到序列推荐(gate recurrent unit for recommendation,GRU4Rec+)中建模序列项目之间的关系,推荐效果进一步提升.Tang等[6]提出了基于卷积神经网络(convolutional neural network,CNN)的序列嵌入推荐模型(sequence embedding recommendation,SER),通过CNN对短期序列的信息进行提取,挖掘项目之间联合级的顺序关系.Ying等[7]利用2个分层注意力网络模型解决了用户长期偏好随时间推进而不断变化的问题.但在上述基于深度学习方法的序列推荐模型中,基于RNN和CNN的模型只能依靠其结构来对序列交互行为提取项目及位置信息[8].基于RNN的模型存在训练过程较难以及难以并行化处理的问题,基于CNN的模型难以捕捉远距离特征以及需要较深的层次才能感知任意行为间的影响[9].
Kang等[10]受到Transformer启发,提出了采用自注意力机制的序列推荐模型(self attention for sequential recommendation,SASRec)来对用户的历史行为信息建模,提取到了更有价值的信息.现有的大多数序列推荐模型过分关注用户短期偏好,而实际上用户的长期行为也包含了大量的信息,由此Zhang等[11]使用自注意力机制提取短期偏好信息,并使用度量学习获取长期偏好.研究者们利用自注意力机制对序列行为进行特征提取,不但更好地建立起各个交互行为间的关联,而且实现了高度并行化计算.但自注意力机制仅通过位置编码来简单引入交互行为中项目的绝对位置信息,其捕捉到的序列位置信息只包含顺序关系[12].这种位置编码限制了用户交互行为间的潜在联系,使其无法反映用户行为被时间跨越尺度大小的影响[13-14].
在上述的序列推荐模型中,虽然可以建模复杂的序列关系,但忽略了序列行为的时间上下文信息,导致模型很难捕捉动态变化的用户兴趣.此外,忽略交互行为间的项目成对关系及边信息也对推荐结果有较明显地影响[15].由此提出一种融合时间上下文和长短期偏好的序列推荐模型(combines temporal context with long-short term sequence recommendation,TCLSRec),利用感知时间间隔的自注意力机制[16]挖掘短期交互行为之间的深层次联系,然后通过注意力权重动态调整获得用户的短期动态兴趣.模型同时考虑用户长期偏好信息和项目间的成对联系,提高推荐准确度.

图1 TCLSRec模型框图Fig.1 Overall structure diagram of TCLSRec model
1 问题定义
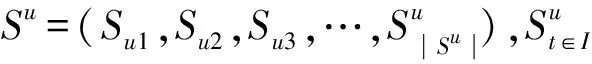
2 模型设计
TCLSRec模型的结构分为4个部分,分别为嵌入层、短期行为处理部分、长期行为处理部分及预测层.TCLSRec的模型如图1所示.
2.1 感知时间间隔的自注意力机制


(1)
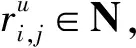
(2)
2.1.1 嵌入表示层 用户短期行为序列的项目嵌入表示EI∈Rn×d,如式(3)所示:
EI=[ms1,ms2,ms3,…,msn]T,
(3)

(4)
(5)
2.1.2 感知时间间隔的自注意力区块层 设置感知时间间隔的自注意力层的输入查询为序列行为嵌入、键和值为序列行为2种相对位置嵌入.则感知时间间隔的自注意力区块层输出序列嵌入表示如式(6)所示:
Z=(z1,z2,z3,…,zn)T,zi∈d
(6)
式(6)中每个输出zi的嵌入表示可由式(7)计算得到
(7)
式(7)中WV∈d×d是可学习的权重矩阵,权重系数αi,j通过式(8)来计算得到
(8)
hi,j是当前项目和序列行为项目序列的关系向量,可由式(9)得到
(9)
式(9)中WQ∈d×d和WK∈d×d是查询和键可学习的2个参数矩阵,d是每个项目的嵌入维度.为了赋予模型非线性,增强模型性能和缓解过拟合等问题,模型在自注意力层之后加入了残差连接、层归一化函数(LayerNorm)、丢弃层(Dropout)和激活函数为ReLu的2层全连接层(fully connected layer,FCN).
其中FCN层输出由式(10)计算得到
FCN(zi)=max(0,ziW1+b1)W2+b2,
(10)
式(10)中W1、W2∈d×d,b1、b2∈d×1,由此最终得到融合了项目信息、项目位置信息和项目之间相对时间间隔信息的联合嵌入表示如式(11)所示:
Zi=LayerNorm(zi+Dropout(FCN(LayerNorm(zi)))),
(11)
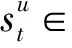
(12)
2.2 长期行为处理

(13)

(14)
式(14)中WP∈d×d,bp∈d×1.最终pu∈d×1是用户的长期兴趣偏好表示.

图2 双线性特征交叉结构Fig.2 Bilinear characteristic cross structure
2.3 门控机制融合层
(15)
式(15)中W3、W4、W5∈d×d,bG∈d×1,最终用户行为偏好表示d×1由式(16)计算得到(⊙是元素乘符号):
(16)
2.4 双线性特征交叉层
在序列推荐问题中对项目成对关系的学习非常重要,联系比较密切的项目在未来的交互序列中可能会连续出现[17].传统元素积的形式难以有效地对稀疏数据进行特征交叉建模且模型的表达能力不强.为了捕捉用户这种项目之间的共现模式,使用双线性交叉函数学习其嵌入表示,其结构如图2表示.
图2中Wp,q∈d×d为参数矩阵,·是内积运算,⊙是哈达玛积,p、q∈(1,2,3,…,m),m为目标项目数量.则运算公式如式(17)所示:
cp,q=vp·Wp,q⊙vq.
(17)
项目p和项目q的特征交叉结果cp,q∈Rd×1通过平均池化聚合为当前项目的嵌入向量表示cp=avg(cp,q),cp∈d.由此将候选项目集的嵌入表示进行双线性特征交叉后得到包含项目联系信息的候选项目集嵌入表示C∈|I|×d.
2.5 预测层
(18)
yi,t表示在时间点t之前给出用户交互序列后,第i个项目成为用户感兴趣的相关性.因此yi,t越高则说明具有更高的相关性,最后根据相关性大小的排序列表进行推荐.
2.6 模型训练
模型训练时定义最终交叉熵损失函数为式(19):
(19)
训练时针对每一时刻的正样本,都会随机生成一个项目j作为负样本来平衡训练过程中的正负样本比例.

表1 数据集数据统计Tab.1 Statistical data sets
3 实验及分析
为了验证提出的TCLSRec模型的推荐性能,采用了TensorFlow深度学习框架,实验采用的操作系统是Windows 10,显卡型号是RTX 2080ti,CPU型号是Intel3×XeonE5-2678v,Python版本为3.7.在集成开发工具Pycharm2020.3.3和TensorFlow2.2.0深度学习框架下进行实验和分析.
3.1 数据集
实验采用了MovieLens-1m(ML-1m)数据集和Amazon公开数据集下子数据集Beauty和Electronics.3个数据集都包含了用户-物品交互的时间戳信息,并且利用项目的种类、品牌等属性以及用户的一些属性作为辅助信息.其中处理过的ML-1m数据集包含了用户编号、电影编号、评分、时间戳信息,电影的相关信息包括名称、上映年份和类别,以及用户的年龄和性别信息.处理过的Amazon子数据集去除了在评论中没有出现过的项目,其中包含的数据类型有评论者编号、评论项目编号、审查评分、评论内容、项目评分、评论关键词以及评论时间戳信息.为了缓解冷启动对模型推荐性能的影响,模型不考虑交互次数少于5的用户和项目交互序列.所使用的3个公开数据集数据统计结果如表1所示.
3.2 评价指标
使用命中率HR@k(hit ratio)和归一化折损累积增益NDCG@k(normalized discounted cu-mulative gain)作为评价指标,其中k为推荐列表的长度,设置k=10来评估模型的好坏.
1) 命中率HR@k是评价推荐结果的召回率,衡量的是推荐算法的准确性,由式(20)计算得到
(20)
其中#users是用户总数,而#hits是测试集中的项目出现在Top-k推荐列表中的用户数量.
2) 归一化折损累计增益NDCG@k则更多考虑所推荐的项目是否出现在用户更容易关注的位置,即强调了推荐列表的顺序性,由式(21)计算得到
(21)
其中r(i)是推荐列表中项目i的相关性分数,如式(22)所示:
(22)
其中p为推荐列表,G为实验测试集,pi表示推荐列表中的第i个项目.
3.3 对比模型及部分实验设置
将对比模型设置为FPMC[2]、GRU4Rec+[5]、Caser[6]、SASRec[10]及AttRec[11].在实验中,将数据集进行处理之后划分为训练集、验证集及测试集.生成的每一个样本序列最后1个项目用作测试,倒数第2个项目用作验证,其余则用作训练.在实验中对于3组数据集,用户和项目的向量表示维度均设置为50,批次大小设置为512,L2正则化系数设置为1×10-6,学习率为0.001,采用Adam优化器优化.模型AttRec和所提出的TCLSRec模型,长期交互序列长度设置为50,短期交互序列的长度设置为10.
3.4 对比实验结果及分析
所提出的TCLSRec模型和其他基准模型的性能对比如表2所示.

表2 TCLSRec与其他基准模型的性能对比Tab.2 Performance comparison between TCLSRec and other benchmark models
通过分析,可得出以下结论:
1) 在Beauty和Electronics数据集上,模型FPMC的指标NDCG@10都优于模型GRU4Rec+和Caser,但是在ML-1m数据集上,FPMC的指标NDCG@10比他们要差.这说明在稀疏数据集上使用时间序列的信息进行序列建模时,其效果要优于一些基于神经网络的模型.
2) SASRec模型在3个数据集中都获得了不俗的效果,这说明使用叠加的多个自注意力层可以捕捉更多的特征变换,从而可以更好地学习到用户偏好信息,相较于传统的基于RNN和CNN的模型取得了明显的优势.
3) TCLSRec模型相较于其他基准模型在不同数据集上均取得了一些提高,相较于SASRec和AttRec模型,TCLSRec模型利用增加感知时间间隔自注意力块来捕捉用户动态变化的短期偏好信息,使用门控机制将长短期行为偏好融合后提取到了更精准的用户偏好信息,进行预测后获得了更好的推荐效果.
3.5 模型消融实验
在3个数据集ML-1m、Beauty和Electronics上对模型进行了消融实验,验证了有无感知时间间隔的自注意力机制和双线性特征交叉层对模型的影响.实验结果如图3所示,其中NT-TCLSRec代表无时间间隔信息的TCLSRec模型,NT-TCLSRec对短期行为偏好进行建模时使用自注意力机制代替.NB-TCLSRec代表无双线性特征交叉层的TCLSRec模型.

(a) HR@10评价指标下的模型效果(b) NDCG@10评价指标下的模型效果图3 3个数据集下的消融实验结果Fig.3 Ablation experiment results on three data sets
根据图3(b)的实验结果可以观察到:首先,在缺少时间间隔自注意力机制时指标NDCG@10在ML-1m和Beauty数据集上有明显下降,这说明增加感知时间间隔的自注意力机制可以更有效地捕获多层次用户兴趣的动态变化,提高推荐效果.其次,使用未进行双线性特征交叉的候选集嵌入表示进行预测,在指标HR@10上只有小幅下降,但指标NDCG@10下降较明显,这说明捕捉项目间的共现模式可以提高推荐的质量,使得感兴趣的项目出现在推荐列表更靠前的位置,从而提高用户满意度.
3.6 超参数对模型的影响
3.6.1 用户和项目维度d的影响 在TCLSRec模型中,超参数d是一个很重要的参数.当d越大时,表示的向量越复杂,包含的信息也越多,但d较大造成模型复杂等问题也会影响最终效果.图4展示了在2个数据集中不同维度下TCLSRec模型的HR@10和NDCG@10性能.从图4上可以看出当维度d=50时,TCLSRec模型在2个不同的数据集上,2个性能指标均取得了最好的效果.由于Electronics数据集与Beauty数据集的数据类型相同,且稀疏度相差较小,则Electronics数据集在不同维度下的实验结果与在Beauty数据集的变化类似.
3.6.2 短序列长度N的影响 为了探究用户短期序列长度对模型效果的影响,在上述参数实验和消融实验的基础之上进一步实验.在长期序列长度设置为50的基础上,将短序列长度设置为5种长度,分别为10、20、30、40和50,以此来观察短序列长度对实验结果的影响.实验结果如表3所示.
由表3可知,在密集数据集ML-1m上,当短序列长度越长时,模型性能反而降低,可能是因为密集数据集的平均交互序列较长.随着短序列长度的增加,序列中噪声增多,导致模型的准确率下降.在稀疏数据集Beauty上,模型的效果保持稳定.这种结果可能是此稀疏数据集中数据处理后的大多数交互序列较短,模型最终的兴趣偏好受短期行为影响较多.当短期序列长度增加后模型效果略有提升,之后趋于平稳.
4 结论
本文提出了一种融合时间上下文信息与长短期偏好的序列推荐模型TCLSRec,该模型首先利用感知时间间隔的自注意力机制捕捉用户短期行为序列与时间上下文的关系,之后将其与长短期偏好通过门控机制融合得到用户兴趣表示.使用双线性特征交叉的方法对候选项目集建模项目共现模式,并与用户兴趣表示一起输入到预测层进行项目推荐.实验结果表明提出的模型在推荐性能上有所提高.
尽管提出的模型在评价指标上略有提升,但是在长期交互行为处理上忽略了不同项目在序列间的相互影响.下一步将继续研究长短期行为的差异和如何有效提取长期偏好,以构建更精准的推荐模型.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
小学生学习指导(低年级)(2019年3期)2019-04-22
商用汽车(2016年11期)2016-12-19
商用汽车(2016年5期)2016-11-28
第二课堂(课外活动版)(2016年2期)2016-10-21
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
读写算·小学低年级(2014年4期)2014-07-24
小雪花·成长指南(2009年10期)2009-12-04
