
云平台中基于HBase的RDF数据存储模型研究
2014-08-07 02:45王静蕾赵明慧
中州大学学报 2014年6期
王静蕾,赵明慧
(1.郑州旅游职业学院 招生就业中心,郑州 450009;2.郑州职业技术学院 机械工程系,郑州 450121)
1 RDF数据存储方式分析
随着“语义网”和关联数据技术产生的RDF数据规模急剧增加,传统单节点RDF数据库必然会出现搜索性能瓶颈,研究人员从RDF存储介质的选择、模型定义以及查询连接处理等方面进行了一些探索,但目前采用的常用解决方案仍是利用分布式计算的相关技术。
因为RDF数据的基本结构是简单的三元组,即Subjeet、Predieate、Objeet,所以无论RDF数据是基于何种关系的数据库之上,首先都必须解决如何存储它的三元组。在众多的存储方案中,基于通用分布式技术的存储方案有RDFPeers,另外还有一些是RDF数据存储优化过的集群方案,如YARS2、4Store、ClusteredTDB。本文基于以上思路,选择利用开源组织 Apache的Hadoop分布式计算平台,将Hadoop与RDF相结合,设计一种合理的存储方式将RDF存储到列数据库HBase中,利用Hadoop的海量存储与并行计算能力来满足RDF超大规模数据存储查询,然后通过MapReduce 编程模型实现并行化RDF 查询操作,从而提升查询性能,解决海量RDF 存储和查询面临的可扩展性及查询性能瓶颈问题。
2 RDF存储系统的模型分析
按RDF数据存储的方式,可以将其分为三种模型。
2.1 Hadoop结合平面文件,代表系统是SHARD
此系统没有根据RDF的三元组的三个分量建立相应索引机制,而是采用平面文件的方式组织数据,将整个数据集存储到HDFS上。缺点是不能有效处理随机查询以及三元组的增加删除操作,另外,为了尽可能的访问多个节点,SHARD将原本逻辑关系密切的三元组哈希分布到集群中的各个节点,这样在执行SPARQL查询时,必须在网络上传输大量的数据,一定程度上影响了查询性能。
2.2 Hadoop结合单机RDF数据库,代表系统是HadoopRDF
该系统采用Hadoop和Sesame相结合的方式构建分布式RDF存储系统,这里的单机RDF指的是在《Scalable SPARQL Querying of Large RDF Graphs》一文中采用的RDF-3X,它利用一种图分区算法将RDF数据集和其可能的组合方式分散存储到集群中的RDF-3x数据库中,不仅如此,RDF-3X还存储了SP、SO、PS等9种统计信息,以辅助生成较优的查询计划。优点是使三元组能够存储在同一个节点上,减少查询时的网络传输延迟。缺点是存储多份数据必然导致对存储空间需求的增长,这使单机RDF数据库在存储和查询上都易发生性能瓶颈,影响到整个存储系统的可扩展性。
2.3 Hadoop结合HBase本文重点阐述的存储方案
HBase(Hadoop Database)是一个构建在HDFS上分布式的、高可靠性和容错性、面向列的、可伸缩非结构化列数据库,是BigTable的开源实现。鉴于它非常适合存储超大规模稀疏数据,而RDF图通常是稀疏的,因此采用HBase来存储RDF数据是一种很常用的方法。目前的研究成果中无论是设计原型系统SPIDER,还是将副本存储到几个HBase表中,或是采用MapReduce处理SPARQL查询,都没有很好的解决HBase表设计模式和查询处理策略,影响了并行查询的性能。
3 基于HBase的RDF存储系统设计
利用HBase存储RDF三元组时,其优势明显。
3.1 数据类型简单,其本身可作为索引的一部分
HBase只有简单的字符串类型,字符串在底层以字节数组形式存储,数据即索引。在存储RDF数据集时,可将三元组的三个分量按字符串形式进行存储,这样可以简化数据维护成本。作为HBase的Crud客户端底层的HTable,即一张排序的映射表,它根据Row Key 或“RowKey,Column Family:Qualifier”快速检索存储单元,将数据存储在Row Key或Qualifier中并作为索引的一部分,可以充分实现三元组模式的快速匹配。
3.2 按列存储稀疏数据,存储利用率高
如前所述RDF数据是稀疏的,如果利用关系数据库来存储会产生很多空值,造成空间浪费。而HBase是基于列存储的,不同行之间可以有不同列,并且空白列不予存储,这样存储空间利用率高。
3.3 提供了MapReduce编程的相关接口,易实现编程模型的集成
HBase只有简单的查询、删除和清空等操作,不存在表和表之间的关系,可以通过MapReduce 编程模型对连接操作进行优化以提高响应速度。
3.4 具有良好的可伸缩所性,适合海量数据存储
HBase的特征之一是灵活的扩展性,可以轻松实现RDF的分布式存储。HBase数据表被设计存储到不同的Region中,一个Region对应一个HRegionServer,Region的个数随着表的增大而增大,均衡分布在集群中的HRegionServer中。由于过程是透明的,用户不必参与负载均衡、数据冗余等操作,当集群满负荷时,只需通过添加硬件资源来应对数据的持续增长。
因此,本文的思路是要实现海量RDF数据的分布式、扩展性、高效性存储与查询,设计基于HBase的RDF的存储系统,基于MapReduce对SPARQL查询中的连接操作进行并行化。
4 基于HBase的RDF存储系统设计
RDF数据均衡存储在构建于HDFS之上的HBase 集群节点中,HRegionServer(域服务器)维护HBase的集群节点并存储RDF数据域(Region)。系统对外主要由两个模块组成,一是RDF 数据映射模块,它的作用是将RDF数据加载到HBase集群以及删除和更新三元组等功能,其中数据加载操作是利用MapReduce 机制实现并行加载; 一是数据查询处理模块,它的作用是提供 SPARQL 查询处理功能,采用 Jena ARQ解析SPARQL。其中,对只有一个三元组模式的查询,直接由三元组模式查询模块响应,而对于非一个三元组模式的查询,则由基本图模式查询模块响应。
由“生成查询计划”模块和“执行查询计划”模块组成基本图模式的查询主体,本文拟使用 Hadoop 的 MapReduce 框架来解决与HBase相关的数据处理问题,基于MapReduce编程模型实现连接操作的并行求解方式,解决提升查询计划描述的一系列连接(Join)任务操作时花费的时间。MapReduce 实现并行查询时只需要一个副本即可,因此,通过一个HBase 表存储一个副本实现海量RDF数据的存储,对于不能进行索引的检索,利用HBase客户端提供的一种高效的表数据存储的数据结构HBaseFilter来解决,它具有仅次于索引的检索速度。对于RDF的存储模式的设计,RDF数据的基本结构为非常简单的三元组,不管RDF数据依托哪种存储系统,首先必须解决如何组织这些三元组。下面从分析三元组的索引策略开始。
4.1 副本及索引策略分析
如表1所示,三元组以
采用这种方案中,当数据量较小的时候,逐行解析并加载到 HBase表中,优点是设计简单、便于理解,很容易实现且具有很好的通用性。可是在海量数据存储的情况下,RDF数据集三元组一般都是至少百万级别,采用串行加载方式会耗费较长时间,同时也会造成过多的副本和自连接, HBase 列数据库本身不具有 ACID特性,很难保证多副本的一致性,从而导致查询结果不全或出现错误,严重影响查询性能。针对这种海量 RDF 数据集的加载问题,采取并行加载方案,主要包括两个步骤,第一步将RDF数据集合并上传到HDFS,第二步将RDF数据集由 HDFS 并行加载到 HBase。
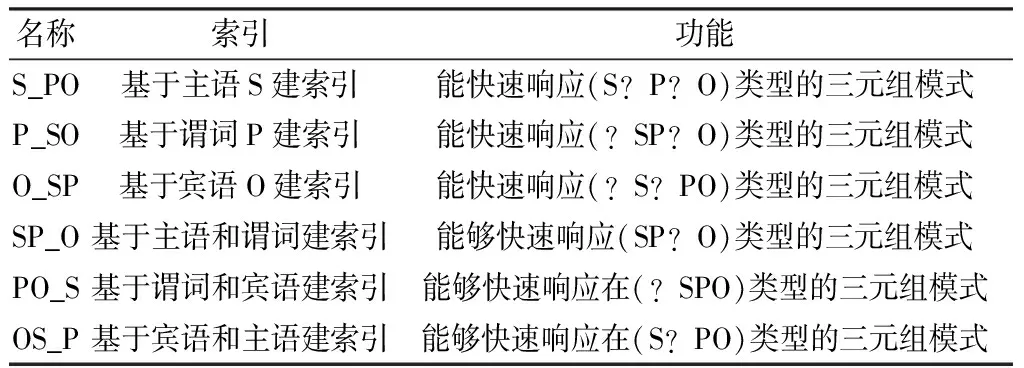
表1 索引和功能
4.2 RDF 存储模型设计
考虑对RDF数据中多对多关系的支持以及对批量加载、更新操作的支持,如在RDF数据集中,谓词两端的主语和宾语通常是多对多的关系,即同一个谓词可能在不同的三元组中出现。以“淘宝网”用户和网店之间的关系“user”为例,一个用户可以选择多家网店,而同一个网店也可能有多个用户。本文以谓词和宾语为关键字的存储模式,将RDF三元组存储在具有一个列族的HBase表中,谓词和宾语存储在RowKey字段,Qualifier字段存储主语,Value字段设为空值。每个KeyValue是一个轻量级的存储单元,存储单元中只存储一个RDF三元组。
这种方式有四个方面优点:一是利用了RowKey按字典排序的特性,通过谓词检索可以得到所有以该谓词为前缀的RowKey,再通过RowKey检索所有的Qualifier,也即实现了二级索引结构。二是利用了HBase表中Value字段变长存储的特性,Value字段为 null 不会造成存储空间的浪费。三是在插入三元组时直接插入即可,如果存在则会自动覆盖,用户不用关心该数据是否已经存在。最后,在删除和更新操作时也是在轻量级 KeyValue 存储单元上实现的,不会出现字段内容过大而导致请求超时的情况。
5 RDF存储系统原型的实现
如前图1所示,基于HBase的RDF存储系统主要由两部分组成,一是RDF数据映射模块,二是RDF数据查询模块。下面依次介绍两个模块的设计原型。
5.1 映射模块
包括将加载RDF数据集、删除和更新RDF中的三元组。数据集较小时,逐行解析和加载便可。对于海量数据集,首先解决是RDF数据上传到HDFS,本文使用HBase的Bulk Load工具,思路是利用MapReduce采用分而治之,先生成HBase内部文件HFile,通过一个递归实现将本地RDF小文件合并上传到HDFS,使用RDFLoad类完成,具体由图1所示的LoadRDF to HDFS()方法实现,每次递归中将每个文件作为输入流,将其传送到HDFS上的同一个目标路径生成的输入流中,最终将实现将整个 RDF 数据集中的小文件完全加载到HDFS中。
解决RDF数据集由HDFS并行加载到 HBase中,方法是通过MapReduce作业将其加载到HBase。对于每个HFile文件,使用HBase的Completebulkload命令将HFile文件上传到HBase集群中。Bulk Load命令会遍历HFile文件里的文件,为里面的每一个文件寻找该文件匹配的HBase Region,并通知该Region所属的Region Server将该文件拷贝到指定存储区域中,同时通知客户端可以获取该数据。
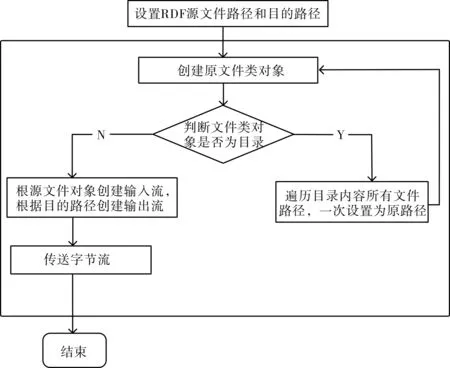
图1 RDF数据加载至HDFS流程图
5.2 查询模块
由于HBase不支持查询语言,但提供Java API对其进行查询与更新,因此本文采用HBase Java API实现SPARQL查询与更新操作。其最重要的两个概念是三元组模式(Triple Pattern)和基本图模式(Basic Graph Pattern, BGP),其中基本图模式是一组三元组模式的集合。本文采用Jena ARQ解析SPARQL语句,在此用一个例子说明整个BGP查询过程。假设user类有三个实例 user0,user1 和 user2,那么以这三个实例为主语的三元组有六个,分别为:
这里Commodity0和Commodity1为Commodity类的实例。如查询名字为"jingleiw"的用户以及他所购买的商品。首先要进行BGP的排序,根据共享变量优先与选择度最高原则,将BGP中的所有Triple Pattern进行重排,方法如下:
BGP: {
tp1:?X’ rdf:type, user.
tp2:?X’ subscriber Of, ?Y.
tpy.?X’ name, "jingleiw ". }
BGP: {
tp1: ?X, name, "jingleiw ".
tp2: ?X, rdf:type, Buysale.
tp3: ?X, subscriber Of, ?Y. }
接下来是按顺序查询每条Triple Pattern。在这里要调用一个推理算法来将输入的Triple Pattern添加到推理结果集中,不再详述,对tp1推理的结果为S1: {(?X, name, "jingleiw")},然后再调用查询算法QueryTP(主语未知,谓词已知)查询每个Triple Pattern,合并查询结果。
R1: {(
R: {(
对tp2进行推理查询, tp2与tp1有共享变量?X,用R中变量?X的已有值user0, user1分别替代中tp2中的变量?X得替代后的tp2的集合TP:{(< user0>, rdf:type, buysale),(< user2>,rdf:type, buysale)}。调用函数 ReasonTP依次查询中的每个Triple Pattern, 对(
R: {
(
(
(
以 (
R:{
(
(< user0>, rdf:type. user0),
(< user0>, subscriber Of, < Commodity0>),
(< subscriber0>,subscriber Of, < Commodity1>)}
6 结束语
本文主要研究了RDF数据集在HBase中的存储方式,具体分析了存储结构和查询方法,但仍有许多问题未详细论述,如在进行查询推理时所涉及的函数设计,这都需要在以后进行进一步研究。
参考文献:
[1]朱敏,程佳,柏文阳.一种基于HBase的RDF数据存储模型[J].计算机研究与发展,2013(S1):23-31.
[2]宋纪成.海量RDF数据存储与查询技术的研究与实现[D].北京工业大学,2013.
[3]程佳.一种基于Hadoop的RDF数据划分与存储研究[D].南京大学,2013.
[4]Manola F,Miller E,McBride B.RDF Primer[EB/OL].[2004-02-10].http://www.w3.org/TR/rdf-primer/.
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
哈尔滨轴承(2020年2期)2020-11-06
五邑大学学报(自然科学版)(2019年3期)2019-09-06
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
发明与创新·大科技(2019年12期)2019-03-17
计算机技术与发展(2018年12期)2018-12-20
小型微型计算机系统(2018年3期)2018-03-27
弹箭与制导学报(2015年1期)2015-03-11
现代防御技术(2014年6期)2014-02-28
