
基于机器学习的个人信用模型实证分析
2020-04-07 11:41张志明
宿州学院学报 2020年1期
张 晖,张志明
铜陵学院金融学院,安徽铜陵,244061
1 引 言
随着信息技术的高速发展和互联网的普及,征信领域发生了巨大的变化。大数据征信逐渐开始取代传统征信模式。传统征信数据来源单一,主要以传统商业银行的违约记录作为征信依据,覆盖人群范围较小,不能准确判断个人实际征信状况。大数据征信以互联网为平台,采用数据抓取和数据挖掘技术,运用合理的算法判断个人或企业的信用状况。其数据种类多样,来源广泛,具备综合判断的能力。近年来,个人信用模型不断完善,从早期的判别分析模型到今天的基于机器学习的个人征信模型层出不穷。本文通过P2P平台,在经过用户允许的情况下,采集1 000名用户的个人信息,运用四种不同的机器学习方法进行对比,将数据按照7∶3比例划分,70%数据用于训练,30%数据用于验证模型,分析在有限数据情况下不同算法的准确度。
2 个人征信模型发展综述
个人征信模型是以评分对象过去的社会经历和交易记录为数据,采用数理统计的方法,分析和判断个人的信用状况。1941年,Durand在其编写的《消费者分期付款信贷的风险因素》一书中,提出了数理统计模型用于消费者授信决策的统计方法[1]。1958年,Fair等利用判别分析法建立了第一个真正现代意义上的商业化信用评分系统FICO,其产品在商业金融领域迅速得到了广泛应用[2]。
计算机和信息技术的发展提高了个人征信模型的数据处理能力。在互联网时代,个人征信的数据来源海量增长,机器学习的方法有助于处理大数据性质的征信数据。基于机器学习的个人征信模型的核心是通过搜集和挖据互联网以及其他平台的数据,把人类的经验通过训练的方式让机器进行学习,经过反复检验后得出正确率高的算法或模型,用于预测个人违约概率。
近几十年来,机器学习算法层出不穷。1967年,Cover和 Hart提出了 KNN算法(临近算法)[3]。其全称为K-Nearest Neighbor,意思是K个最靠近的邻居。20世纪80年代,Breiman等人发明了决策树算法,通过反复二分数据进行分类或回归,大大降低了计算量[4]。2001年,Breiman在决策树的基础上提出了随机森林算法,利用多棵树对样本进行训练和预测[5]。朴素贝叶斯分类器(Naive Bayes Classifier,或NBC)发源于古典数学理论,有着坚实的数学基础以及稳定的分类效率。同时朴素贝叶斯模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单[6]。从理论上来看,朴素贝叶斯模型与其他方法相比误差较小,但由于假设条件严格,现实中往往并不成立。1995年,Vapnik等人对线性分类器提出了另一种假设,即支持向量机(Support Vector Machine,简称SVM),其核心思想是寻找一个超平面把数据集的样本空间划分成不同的样本用于分析判断[7]。
综上所述,可以看出当前机器学习数据处理方法取得了诸多的成果,并运用到了个人征信领域中。如美国金融科技公司ZestFinance的个人信用评分模型,从3 500个数据项提取70 000个变量,利用10个预测分析模型进行训练和学习,从而分析消费者的信用状况[8]。国内支付宝旗下的芝麻信用以及腾讯金融、京东金融等互联网金融平台也都纷纷建立了自己的信用评分体系。
3 实证分析
3.1 数据描述
本文数据来源于P2P平台贷款客户资料,变量指标共14项,分别为“年龄”“职业”“收入”“婚姻状况”“教育程度”“存款”“房产”“车辆”“网购消费金额”“债务余额”“违法记录”“公积金”“支付宝年龄”“违约记录”。
3.2 数据处理
上述征信数据中,既有文本型数据,也有数字数据,原始数据无法直接适用于评估模型。同时,数据中的连续变量可能造成数据之间不同的区分度,因此需要对连续变量做进一步编码,使得编码后的数据能够充分反映变量的变化,可以被模型充分学习。
年龄变量是一个连续型变量,其数值对客户信用可能呈“U型”分布,即在年龄数值较小时或较大时对客户可信度具有负作用,中间数值呈正作用[9]。因此直接使用数据作为判断依据,可能对线性模型的评估带来障碍,需要对数据进行重新编码。针对年龄变量,以5岁为一个阶段划分区间,将年龄数据分为:(0,15]、(15,20]、(20,25]、(25,30]、(30,35]、(35,40]、(40,45]、(45,50]、(50,55]、(55,60]、(60,65]、(65,70],共12个区间。通过重新编码,将年龄1维数据转换成12维数据,让模型避免“U型”难点。经过重新编码后部分结果如表1所示。
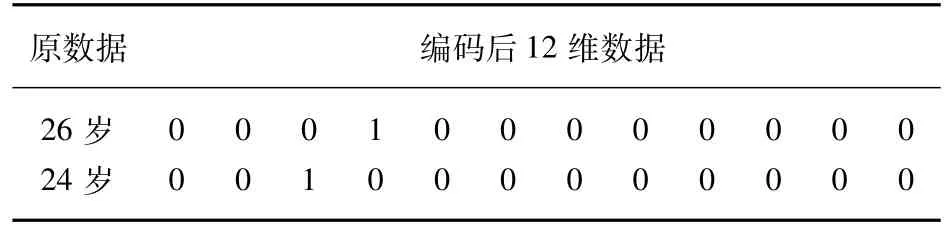
表1 年龄变量数据处理
收入数据按照2017年个人所得税征税级距为梯度划分。收入数据虽然不存在“U型”数据难点,但是工资的额度增加不一定与信用评分呈线性关系,因此需要对工资进行再编码,使工资变换能够被分类器学习,并将收入映射到梯度区间。但是,由于其数值较大,可能会带来因数据单位不一致带来的参数变化,使得模型泛化能力较低,因此对其取以2为底的对数。一方面可以反映数据的变化趋势,另一方面可压缩数值,避免因为数据变化造成模型的效果差。与年龄不同的是,工资的每个阶段都有实质作用,因此需要记录每个阶段的数值,处理后部分结果如表2所示。
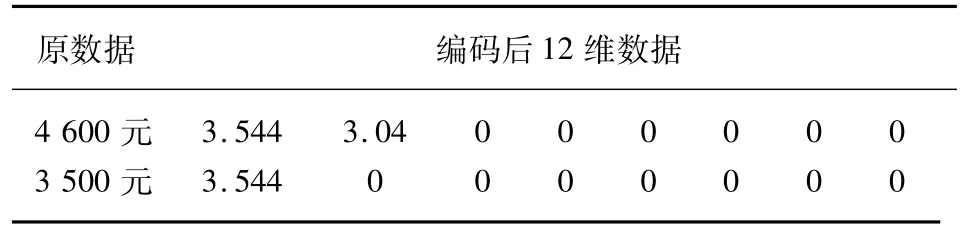
表2 收入变量数据处理
职业划分按照商业银行个人信用评估的一般标准,划分为无职业、个体、教师、医护人员、职员、公务员和金融从业者。其中职员又可分为初级职员、中级职员和高级职员。在职员部分做进一步编码如表3所示。
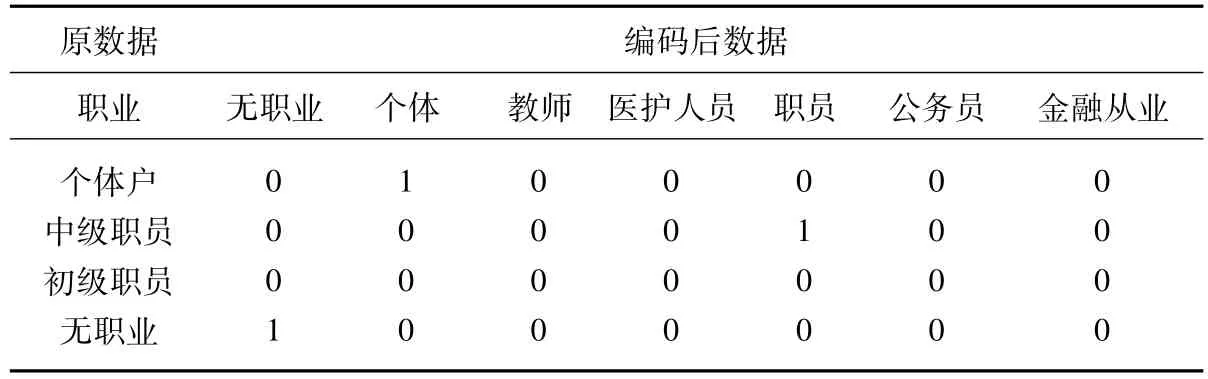
表3 职业变量数据处理
网购消费金额一般数值较大,通过对其进行标准化数据压缩,将原始数据映射到[0,1]区间,避免因数据数值过大带来的模型误差,部分结果见表4。
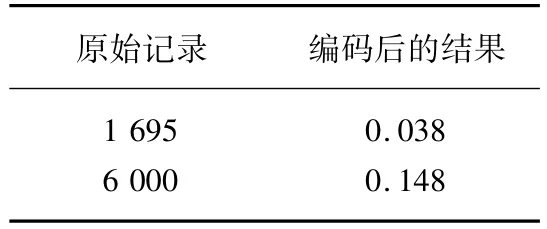
表4 网购消费金额变量处理
存款数据数额较大,在处理上对其以2为底取对数,进行压缩,部分结果如表5所示。
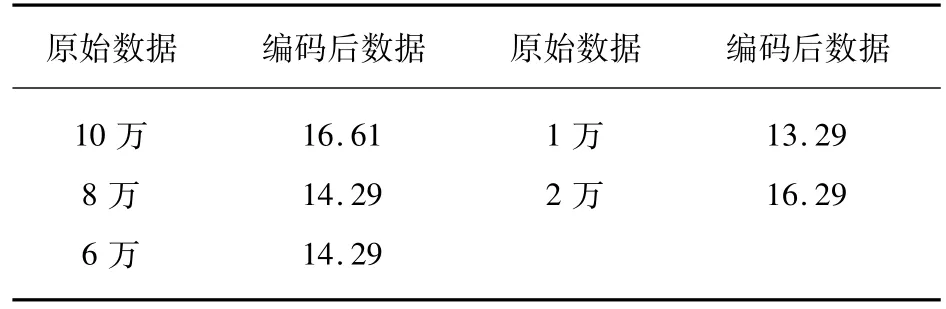
表5 存款数据变量处理
教育程度范围大致可分为,小学、初中、高中、本科、硕士、博士。受教育程度是一种递进关系,适合使用连续编码方式表示,处理结果如表6所示。

表6 教育程度变量处理
债务余额记录可分为:房贷、车贷和其他贷款。原始数据中有很多数据表示不明,无法确认具体贷款额度,所以在操作中将其标记为是否有该项贷款,确认贷款信息,部分结果如表7所示。
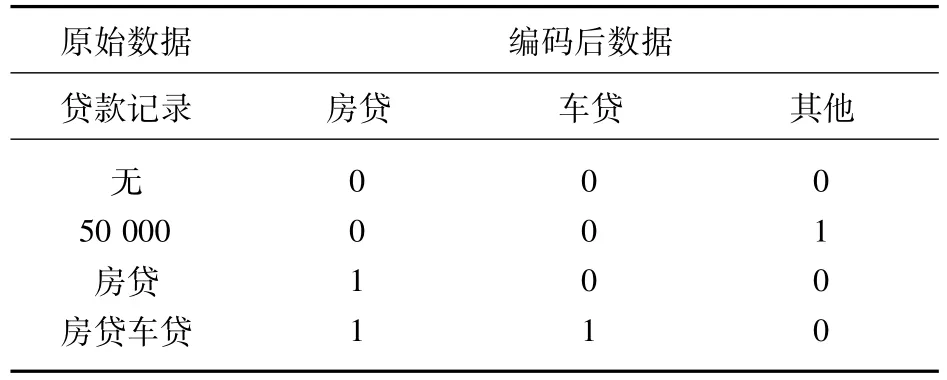
表7 债务余额变量处理
房产、车辆、公积金信息根据有无划分为1、0,婚姻状态未婚为0,已婚为1,离异为2;支付宝年限可以直接使用。
3.3 模型选择
分别选用SVM、决策树、随机森林、朴素贝叶斯进行个人信用数据分析,对比不同模型的分析结果。
SVM本质上是针对线性可分情况进行分析,通过设置软间隔距离,保证了分类的泛化性,降低过拟合情况。当分类特征是非线性时,通过非线性映射算法,将低维非线性特征映射成高维空间乃至无穷维,使其线性可分。从而使得利用线性分割法完成对非线性空间的划分[10]。方案使用高斯核函数将输入向量映射到高纬空间,借助网格搜索法,调节“软间隔”距离,选择最优训练模型。
决策树主要包括ID3,C4.5和CART。信息增益是ID3的分裂标准,它定义了一个特征的信息量:携带的信息越大,该特征在分裂筛选过程中权重越大。实践发现:以信息增益为分裂标准时,分裂过程中偏向于选择数据种类较多的分类属性。C4.5将信息增益率作为划分标准,优化了ID3弊端,但仍旧难以避免决策树中结构复杂、规模大、运行效率低等问题。CART使用GINI系数,在前人的基础上,降低了决策树复杂性,提高决策树算法执行效率[11]。方案使用CART算法,以单个最小节点为2个样本点为分割终止点,对分类器进行评价。
随机森林从bootstrap重采样法等角度,构建集成决策树可缓解上述问题。本方案通过使用35棵CART决策树,以GINI系数为分割依据。通过网格化自动搜索,不同的分割深度、最小分割样本点数等参数,选择最优训练模型。
朴素贝叶斯方法是基于贝叶斯定理的一组有监督学习算法,即“简单”地假设每对特征之间相互独立。尽管其假设过于简单,在很多实际情况下,朴素贝叶斯工作得很好,特别是文档分类和垃圾邮件过滤等数据量大,特征稀疏的分类环境。方案使用服从多项分布数据的朴素贝叶斯算法,将alpha平滑因子设置为1进行分类。
采用Pyhton3.6.0软件,根据常规搜索算法调整模型参数,将数据随机分成训练数据和测试数据两份,比例为7∶3。训练数据用于训练模型,测试数据用于对模型进行评价。评价指标主要包括准确率、召回率和F1值。准确率是评估捕获的成果中目标成果所占得比例;召回率是从关注领域中召回目标类别的比例;F1值则是综合这二者指标的评估指标,用于综合反映整体的指标。结果如表8所示。
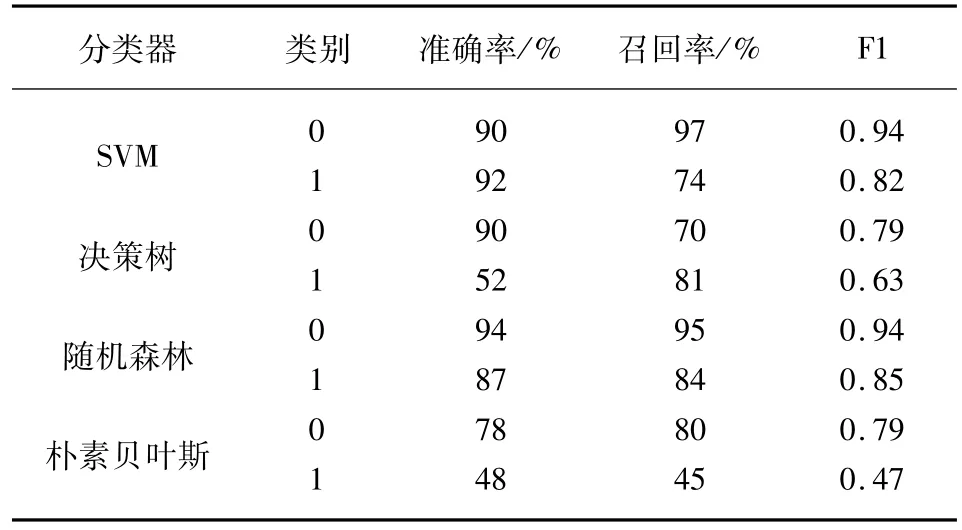
表8 机器学习个人征信模型测试结果比较
结果显示:(1)从准确度来看,SVM和随机森林算法的个人信用评价明显好于朴素贝叶斯和决策树,其对正常用户分类的准确率分别为90%和94%,对违约用户分类的准确率分别为92%和87%。将SVM与随机森林对比发现,SVM能更好地捕捉违约用户,随机森林可以更好地捕捉正常用户。(2)从召回率来看,SVM对正常用户的召回率最高达到97%,随机森林对违约用户的召回率最高达到84%,说明上述机器学习的算法,能够有效地将目标用户查全,避免遗漏。结合F1值来看,SVM和随机森林算法在综合评价方面同样表现较好。
4 结 论
本文通过搜集和整理P2P平台1 000名真实客户信息,运用4种不同的机器学习算法对客户的信用进行分类评价,并对各算法结果进行比较。结果表明:机器学习个人征信模型相比传统个人征信评价在数据来源相同的情况下,可以避免主观上的失误,结果更加明确和直观。从实际效果来看,SVM和随机森林是当前较为成熟的个人征信模型算法,准确度和召回率较高,可适用于商业银行、P2P、小贷公司等机构进行个人征信评价。机器学习算法在样本数量较少、个人数据相对不足的情况下也能够对个人征信有着较为准确的评价。在大数据背景下,未来个人征信数据将会更加充足,基于机器学习算法的个人征信模型可以进一步优化数据处理和算法,提高个人征信评模型的准确度。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
法律方法(2021年4期)2021-03-16
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电影(2018年8期)2018-09-21
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
郑州大学学报(医学版)(2015年1期)2015-02-27
