
中国南北方汉族人群DNA甲基化表观遗传差异研究*
2022-07-21 11:51孙昌春许继臣郭晓媛1赵雯婷李彩霞
生物化学与生物物理进展 2022年6期
孙昌春 许继臣 江 丽 郭晓媛1, 赵雯婷 叶 健* 李彩霞*
(1)山西医科大学法医学院,太原 030001;2)公安部物证鉴定中心,法医遗传学公安部重点实验室,现场物证溯源技术国家工程实验室,北京 100038)
饮食、气候等环境因素可能会影响人的表观遗传学结构[1‑3]。DNA甲基化是一种重要的表观遗传标记,具有遗传稳定、含量丰富、随龄变化等特点[4]。伴随高通量的DNA甲基化数据的不断涌现,大量与肿瘤等疾病发生相关的DNA 甲基化位点被发现[5]。在法医学领域,DNA 甲基化已被用于年龄推断[6‑9]、组织属性判别[10]、同卵双胞胎的鉴别[11‑12]等。基于欧美等国外人群的研究证明DNA甲基化在族群地域间存在差异[13‑14]。
汉族是世界上人口最多的民族。研究表明,汉族人群具有混合特征[15],呈现明显的南北分化,在基于STR[16]、线粒体DNA(mtDNA)[17‑18]、Y染色体SNP[15]、常染色体SNP[19]等遗传标记的研究均已表明汉族内部存在明显的南北遗传差异。北方人群由于受到来自中亚和欧洲遗传成分的影响,呈现东西走向的变化趋势,南北方人群遗传的差异以秦岭淮河到长江为地理分界[20]。汉族人群与当地少数民族之间的遗传差异小于南北方汉族之间的遗传差异[21]。已有研究多局限在DNA遗传标记层面。中国不同地域的气候、饮食等环境因素有很大差异,目前缺乏不同地域人群之间是否存在表观遗传学差异相关研究。本文应用表观基因组关联分析(epigenome‑wide association study,EWAS)技术研究了中国南北方汉族人群之间DNA甲基化的差异,并结合机器学习等算法构建了DNA 甲基化南北方汉族人群推断算法。
1 材料与方法
1.1 样本信息
本研究使用的483 份汉族男性DNA 样本来源于国家科技资源共享服务平台计划项目,使用Illumina 的甲基化芯片Infinium MethylationEPIC BeadChip(简称850K芯片)检测(科技部备份号:*BF2020121803316),850K 芯片可以检测整个基因组860 000 个CpG 位点,覆盖CpG 岛、启动子区、编码区、开放染色质和增强子区域。样本的数量和年龄、性别信息分别见表1及附件表S1。本研究通过公安部物证鉴定中心伦理委员会审查(编号:2017‑001),所有参与者均签署了书面知情同意书。
1.2 质量控制
使用R 软件的ChAMP 包对低质量数据进行预处理,根据以下原则过滤探针:检测到原始探针的P 值大于0.01 的甲基化位点;在大于等于5%的样本的beads 数目小于3 的探针;非CpG 探针;是SNP 或探针覆盖区域内存在SNP 的探针[22];被鉴定为 交 叉反 应 的探 针(cross‑reactive or multi‑hit probes)[23],以及性染色体上的探针。分析得到每个探针位点的甲基化β 值,然后应用BMIQ(beta‑mixture quantile)方法进行β 值的归一化处理。使用奇异值分解(singular value decomposition,SVD)方法检测是否存在批次效应与甲基化水平的关系[24]。
本研究中样本的DNA 提取自外周血,外周血中不同的细胞类型DNA 甲基化特征都不相同,细胞类型组成是EWAS 分析中的一个潜在混杂因素。使用ReFACTor 算法[25]计算不同细胞类型组成的主成分并在GLINT 软件下游分析时将其添加为协变量,从而减少细胞类型对EWAS 分析结果的影响。参考Teschendorff 等[26]研究,设置参数K=7(7 种细胞类型,嗜酸性粒细胞、中性粒细胞、单核细胞、B 细胞、NK 细胞、CD8+ T 和CD4+ T细胞)。
1.3 位点筛选及评估
通过EWAS 结合机器学习Lasso 回归的方法筛选南北方汉族人群的差异甲基化位点。GLINT 软件[27‑30]基于Python2.7 开发,可以实现组织异质性校正和EWAS分析两种功能。基于上述质量控制后的DNA 甲基化矩阵文件,首先对南方汉族和北方汉族人群进行二分类编码,南方汉族编码为1,包括江西汉族和四川汉族,北方汉族编码为0,包括山东汉族、山西汉族和河南汉族,并以此编码用作表型文件,通过GLINT 软件的数据管理功能(data management)检测并删除异常值。然后使用ReFACTor 算法校正组织的异质性(adjusting for tissue heterogeneity),最后对生成的数据文件进行EWAS分析,删除染色体X和Y中的位点,删除非特异性的位点[31]。年龄和细胞类型用作协变量。
使用Lasso 分析方法进一步筛选位点,使用R(version 4.0.2)软件的glmnet 包建立Lasso‑logistic回归模型。该模型是通过构造惩罚函数实现变量选择和参数估计,通过将其回归系数设置为0的方式剔除呈现共线性或者与因变量没有相关性的冗余变量[32‑33],选择对因变量影响较大的自变量并计算出相应的回归系数,最终得到一个预测模型。
使用R 软件基于每个DNA 甲基化差异位点在中国南北方汉族群体的甲基化水平表达特征进行可视化展示。使用R软件softmaxreg包构建多元逻辑回归模型,通过十折交叉验证的方法评估模型的准确性。其中多元逻辑回归使用caret 包中的createDataPartition函数从训练集的每个标记人群中随机采样70%个体构建模型,其余30%个体测试模型准确性,使用confusionMatrix函数对上述模型进行评价;十折交叉验证则是使用caret 包中的createFolds函数对数据集进行划分,将数据集分成10 份,轮流将其中9 份作为训练集构建模型,1 份作为测试集来测试模型的准确性。为了使结果更加精确,每种算法运行10 次,使用seed 函数设定随机数的初始值,产生不同的样本组合,10 次结果的均值作为对算法精度的估计。模型评价指标包括Kappa 系 数、 灵 敏 性(sensitivity)、 特 异 性(specificity)、阳性预测值(PPV)和阴性预测值(NPV)。
2 结果与分析
2.1 73个CpG位点的筛选
483 例汉族男性样本数据的EWAS 分析结果见图1。挑选355 个差异性显著的CpG 位点(P <1×10-6)。使用Lasso回归进一步筛选位点剔除冗余变量。Lasso 回归的特点是在拟合广义线性模型的同时进行变量筛选和复杂度调整。变量筛选是指有选择的把变量放入模型从而得到更好的性能参数。复杂度调整的程度由参数λ 来控制,λ 越大对变量较多的线性模型的惩罚力度就越大,从而精简变量,结果见图2a、b。根据图2a曲线最低点确定惩罚值λ,在图2b的相应惩罚值的位置确定出模型最后所纳入的变量,最终筛选出73 个CpG 位点,位点信息具体见表2。

Fig.1 Manhattan diagram of EWAS analysis results

Fig.2 Characteristic variable screening based on Lasso regressionThe figure shows the process of selecting the most appropriate value of parameter λ in the Lasso model by cross‑validation. (a) Lasso regression cross‑validation of the optimal parameter atlas.(b)Sites in the model of regression coefficient.
Continued to Table 2

Continued to Table 2
2.2 位点的评估
73 个CpG 位点在南北方汉族群体的甲基化水平表达特征如图3 所示,蓝色代表北方汉族群体,红色代表南方汉族群体,图中的白点是中位数,小提琴图中的黑色粗条范围是上下四分位数,外部形状即为分布密度。可以看出这些甲基化位点在两个群体中具有不同程度的差异。73 个CpG 位点的南北方汉族群体的主成分分析结果见图4。图4a可以看到,前两个主成分解释变异的23%,基本可以区分南北方汉族人群。图4b 中不同汉族人群用不同颜色标注,南北方汉族人群较各亚人群之间的差异更大,北方人群中的河南汉族相对居中。绝大部分的江西汉族和四川汉族与山西汉族和山东汉族可以很好地区分开来。
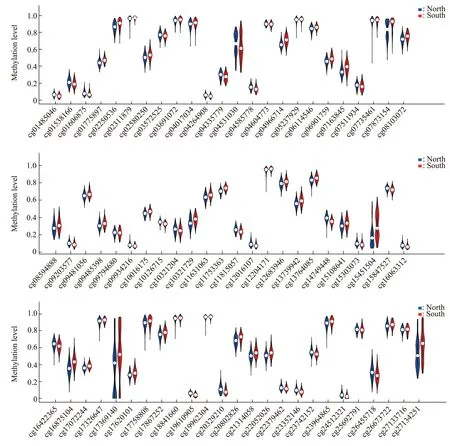
Fig.3 Violin diagram of methylation levels of 73 CpG sites in northern and southern Han populations
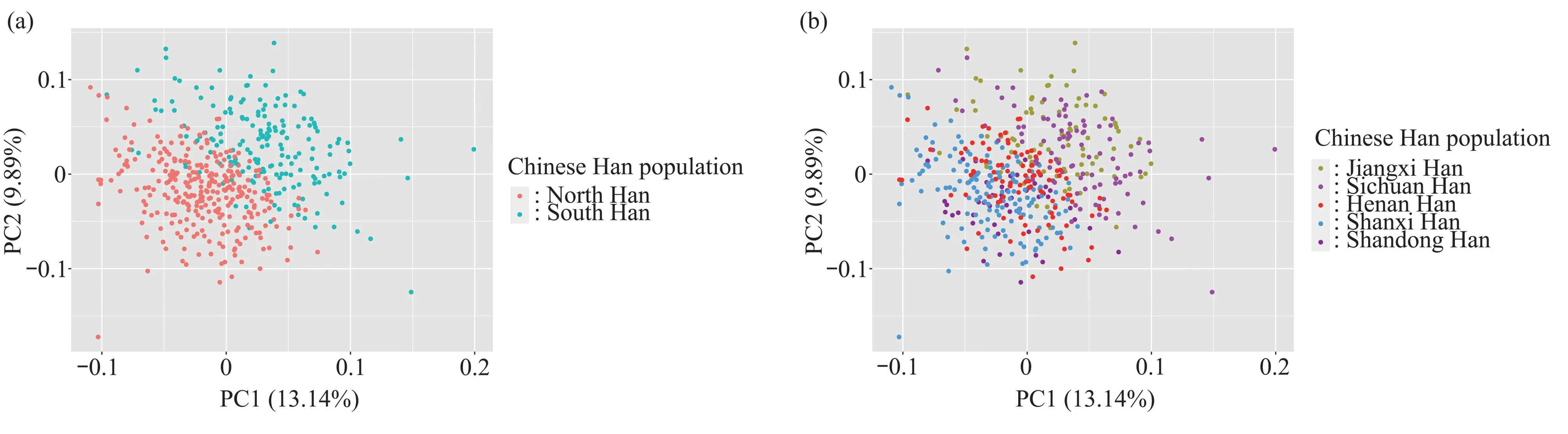
Fig.4 Principal component analysis of northern and southern Han populations using 73 CpG sites(a) Principal component analysis of northern and southern Han populations. (b) Principal component analysis of Han populations of different province.
模型构建与评估10 次重复的结果具体见表3,最终多元逻辑回归30%测试集的预测准确率为99.03%。Kappa系数均值为0.979 6;灵敏性是两个相关个体正确归类为相关的概率,特异性反之,分别为0.990 7 和0.989 5;阳性预测值是判为相关个体中有多少是真的相关,阴性预测值反之,结果分别为0.993 1 和0.986 2。10 次十折交叉验证的结果均在98%以上,最终平均准确率为98.79%,其余各项模型预测性能指标均超过0.95。
3 讨 论
环境因素可通过表观遗传机制,如诱导DNA甲基化模式改变等,在不改变DNA 序列前提下,改变基因表达,从而引发表型变化。法医学研究已经发现大量不同组织之间、不同年龄之间存在差异的DNA 甲基化位点,并构建预测模型[6‑10]。不同地域的气候、饮食等环境因素存在差异,环境通过影响DNA 甲基化水平进而影响基因表达,使得生物表型发生变化,进而造成不同地域人群间的差异。Fraser 等[13]研究北欧(CEU)和西非(YRI)多个家系的DNA 甲基化数据,发现在族群内和族群间存在显著的甲基化差异,这种差异可能来自等位基因突变、上位效应,以及基因跟环境之间的相互作用,还发现在转录起始位点附近的DNA 甲基化有群体特异性。Yuan 等[14]研究了509 份胎盘的450K甲基化芯片数据,基于甲基化位点进行亚洲、非洲、及高加索人群的推断,准确性为0.938。东亚是全球人口最多的区域,占全球人口的22%,汉族是东亚主体民族,大量基因组学研究发现汉族内部存在明显的南北遗传差异,然而目前缺乏针对不同地域汉族人群的表观遗传学差异研究。
本文研究了483份汉族个体的甲基化数据,虽然南方人群没有使用广东广西样本,而是相对靠北的江西和四川人群样本,仍然研究发现了南北方汉族人群之间的甲基化差异,并最终筛选出73 个CpG位点。图4a、b展示了不同地域人群间的甲基化差异,这些差异可能归因于等位基因频率的差异以及上位效应或基因与环境的相互作用[13]。地理学第一和第二定律指出地物之间的距离越近,相关性越大;空间隔离又造成地物之间的空间异质性[34‑36]。从图4b 可以看出河南汉族居中,可能是因为河南在地理位置上属于华中地区,地理位置接近的人群之间的基因交流频繁,遗传距离接近,遗传差异度就小。对于距离相近的人群往往需要更多的位点和更大的参考人群数据才可以实现精确区分。模型预测性能验证采用多元逻辑回归随机抽取70%个体构建模型,30%个体进行测试以及十折交叉验证的方法。未来可增加样本量进一步验证这一组甲基化位点的人群区分准确性。
生物体的一些性状是由多基因共同控制的,其测量值可以用连续的数量进行表示,这些性状统称为数量性状(quantitative trait,QT)。遗传变异可以调节多种机体代谢功能,包括DNA 甲基化在表观遗传学中所表现出的基因表达调节作用。目前比较重要的一种研究方法称为数量性状定位分析(quantitative trait locus,QTL),即定位控制数量性状的基因位点在基因组中的位置。DNA 甲基化数量性状位点分析(DNA methylation quantitative trait locus,meQTLs)是以DNA甲基化作为数量性状,探讨DNA 甲基化水平与基因表达之间关系[37‑38]。除了年龄、性别以及疾病等环境因素会影响个体的甲基化水平,DNA 序列也会对甲基化产生影响,尤其是特异性SNP 的改变。有研究发现非洲和欧洲祖先群体之间70%的差异甲基化位点至少与一个meQTL相关[39],这表明很大一部分的DNA甲基化的群体差异可能主要是由DNA序列变异引起。而从表观遗传角度入手实现地域人群的区分关键在于寻找独立于SNP 的甲基化位点,从而作为STR、SNP等基因组遗传标记的有效补充。
近距离人群的区分和推断是法医DNA 领域的难点之一。目前已报道的AISNP 体系初步实现了东亚南北方人群的区分,未来结合表观遗传标记,有望实现更加精细的人群区分。本文探索研究了利用甲基化进行不同地域人群推断的可行性,研究表明南北方汉族人群之间存在表观遗传差异,未来需进一步增加人群数据获取更多地域相关甲基化位点,与族群相关SNP 位点配合使用实现东亚人群的精细区分。
附件 PIBB_20210091_Table_S1.xlsx 见本文网络版(http://www.pibb.ac.cn或http://www.cnki.net)。

Table 1 Size of samples used in this study
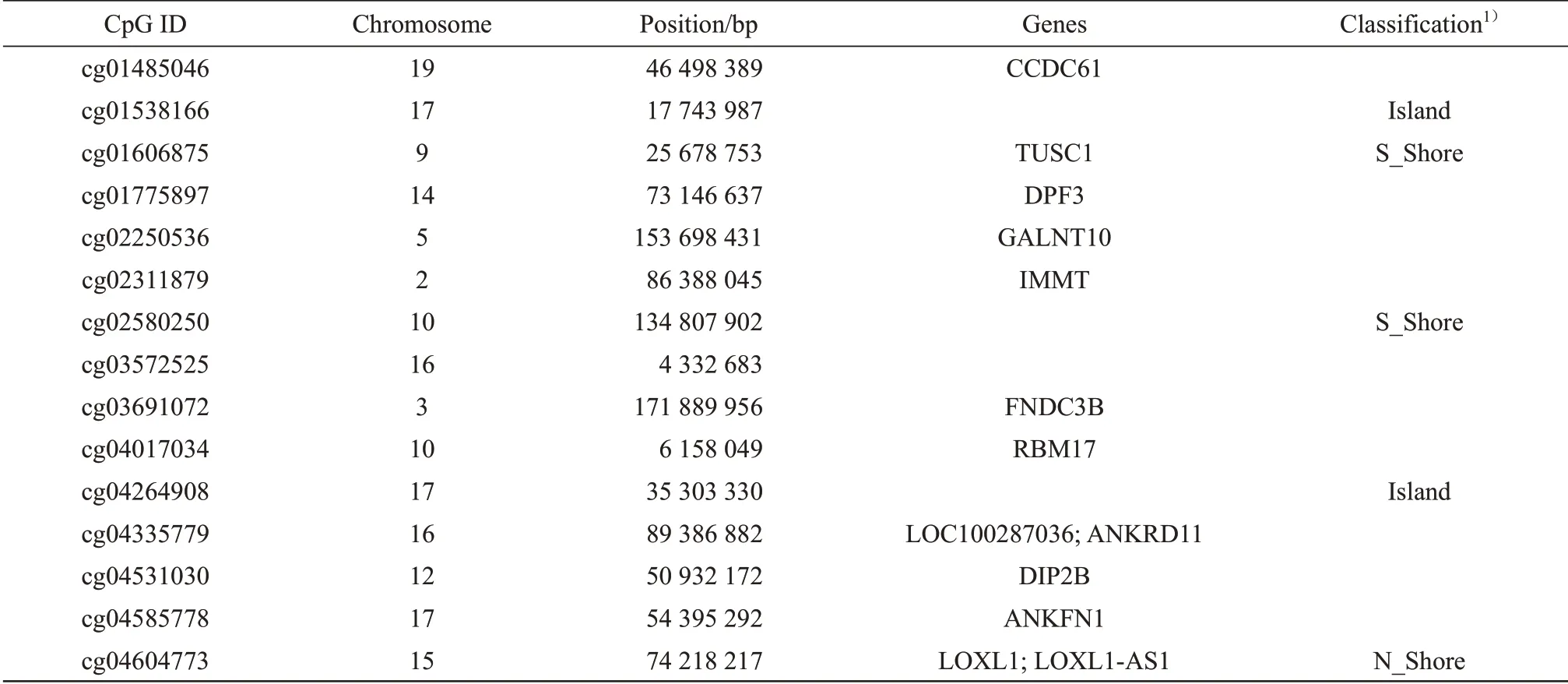
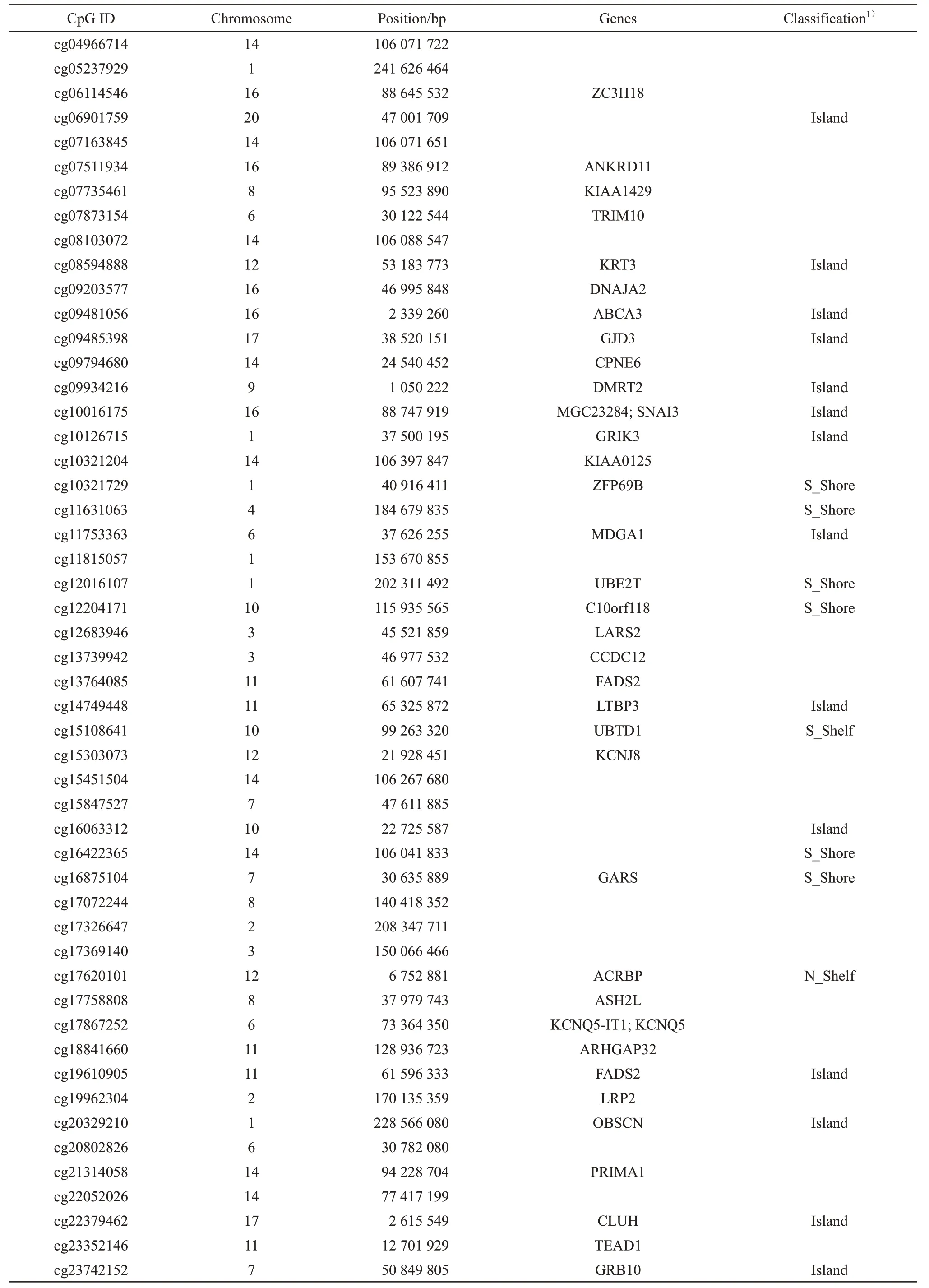
Table 2 Information of the 73 CpGs

Table 3 The performance statistics of the prediction model
猜你喜欢
中国计划生育和妇产科(2022年5期)2022-11-16
分子催化(2022年1期)2022-11-02
中国农业科学(2022年16期)2022-09-19
上海师范大学学报·自然科学版(2022年3期)2022-07-11
中国农学通报(2022年13期)2022-05-31
电脑报(2020年40期)2020-11-06
健康之友(2020年1期)2020-03-24
福建基础教育研究(2019年10期)2019-05-28
电脑知识与技术(2018年19期)2018-11-01
