
基于APARCH模型对中美股市波动风险的研究
2024-03-14 04:25王伟杰沈慈慈通讯作者
商展经济 2024年4期
王伟杰 沈慈慈(通讯作者)
(淮北理工学院教育学院 安徽淮北 235000)
1 引言
中美两国是世界前两大经济体,在世界经济中具有举足轻重的作用。股市是经济的晴雨表,一个国家股市的良好有效发展,对该国整体经济的优化发展起到积极作用。本文以中美两国的股市为研究对象,选取代表中国股市的上证综合指数(Shanghai composite index,SSEC)与代表美国股市的纳斯达克指数(National Association of Securities Dealers Automated Quotations,NASDAQ)为研究对象,借助APARCH模型和VaR方法对中国股市和美国股市的波动性进行研究,并对两国的投资者在进行投资决策时提供必要的参考。
2 文献综述
M Benoit(1963)发现,时间序列的波动过程具有显著的波动聚集现象;Fama(1965)发现,股票的波动过程具有尖峰厚尾性;Engle(1982)提出自回归条件异方差(Autoregressive Conditional Hetero-Scedasticity,ARCH)模型;Bollerslev(1986)提出广义自回归条件异方差(Generalized Autoregressive Conditional Hetero-Scedasticity,GARCH)模型;Ding等(1993)提出非对称幂自回归条件异方差模型(Asymmetric Power Autoregressive Conditional Hetero-Scedasticity,APARCH模型);G30集团(1993)首次提出用在险价值(Value at risk,VaR)度量证券市场的风险,摩根银行(1994)提出VaR的计算方法,并指出利用VaR度量证券市场的系统性风险。
玄海燕等(2021)运用双线性GARCH模型和VaR方法对汇率风险进行检测,结果显示双线性GARCH模型在t分布下比其他GARCH模型的拟合效果更好,可以提高VaR计算的准确性;赵兴等(2022)利用CEEMDAN-ARIMA-GARCH模型对国际原油价格进行预测,结果表明CEEMDANARIMA-GARCH模型在准确度和灵敏度上具有显著优势,其预测精度最高;徐伟民和肖坚(2022)采用GARCH-VaR模型测度中国碳金融交易价格风险水平,结果表明中国碳金融交易价格总体风险水平较高,上海和北京交易市场价格风险超过6个市场价格风险的平均水平,剩余4个市场低于6个市场平均价格风险水平;吴鑫育和张静(2022)将时变风险厌恶指数(RA)引入GARCH-MIDAS模型中,采用损失函数和MCS评价不同模型的样本外预测精度。实证结果表明RA对黄金期货市场波动具有显著的正向影响;相比其他模型,引入RA的GARCH-MIDAS-RA模型拥有更好的参数估计结果和预测结果;王孜(2022)利用上海证券交易所的数据构建GARCH模型,发现融资业务会平抑股票市场的波动,融券业务则会加剧股票市场的波动;熊政和车文刚(2022)根据各项准则构建ARIMA-GARCH-M模型,对股票的收盘价进行预测,利用递归思想对拟合曲线进行校正,进一步提高预测的准确率,并进行MAP、RMSE和EC检验,最后将ARIMA模型、ARIMA-GARCH模型和ARIMA-GARCH-M模型的检验结果进行比较。结果表明,通过递归校正的ARIMAGARCH-M模型在股票短期预测中有着良好的效果,具有一定的可行性;蔡斌坚(2022)使用2015年8月11日—2022年11月30日人民币兑美元汇率的日交易中间价数据进行研究,结果显示汇率存在杠杆效应,使用最佳拟合效果的EGARCH(1,2)模型对汇率序列进行回测分析,并提出相关建议;熊靖波和张晓磊(2022)以2019年1月2日—2021年4月30日中国上证综合指数和美国纳斯达克指数的日度数据为基础,用DCCGARCH模型对新冠疫情冲击下的两国股市的动态相关性进行研究。结果发现,新冠疫情蔓延对两国股市冲击巨大,导致股市相关性程度上下急剧波动,但两国股市相关性始终为正,表明新冠疫情对两国市场产生同步影响。
3 理论分析
波动率的大小代表证券市场风险的高低,虽然波动率的大小不能被直接度量,但是可以选择金融资产的收益率替代波动率来研究股市风险。Bollerslev(1986)在ARCH模型的基础上提出GARCH模型,GARCH(m,s)模型的数学表达式为:
式(1)(2)中:a0>0,ai≥0,βi≥0;当i>m时,βj=0。
Ding等(1993)提出APARCH模型,APARCH(m,s)模型的数学表达式为:
式(3)(4)中:µt为条件平均值;δ大于0;D(0,1)为标准正态分布;系数ω、αiγi和βj满足一定的正则性条件,使得波动率大于0。
在险价值(Value at risk,VaR)是金融市场中应用最广泛的风险度量方法,是指在证券市场正常波动的情况下,在给定了置信水平α和持有时间tΔ 内,投资组合P预期的最大损失,数学表达式为:
式(5)中:PΔ 为投资组合P在持有时间tΔ 内的损失。
4 统计学分析
本文选取中国股市的上证综合指数(SSEC)与美国股市纳斯达克指数(NASDAQ)的日对数收益率序列数据作为研究样本,其中SSEC选取的时间段为2000年1月4日—2023年6月30日,共包含5692个样本数据;NASDAQ选取的时间段为2000年1月3日—2023年6月30日,共含有5912个样本数据,本文的数据均来自同花顺,所有实证结果均使用R软件得到。
中国股市收益率波动呈现波动聚集现象,低波动周期持续的时间长,高波动周期持续的时间短,序列在平均收益的上下两侧进行波动,且方差值具有时变性。SSEC和NASDAQ存在相似的变化趋势,NASDAQ的波动幅度比SSEC的波动幅度更剧烈,表明美国股市的风险高于中国股市的风险,如图1所示。

图1 SSEC和NASDAQ对数收益率序列的时序图
由图2可知,SSEC和NASDAQ序列的Q-Q图与正态分布的Q-Q图不重合,表明SSEC和NASDAQ的收益率序列是偏向非正态分布的。
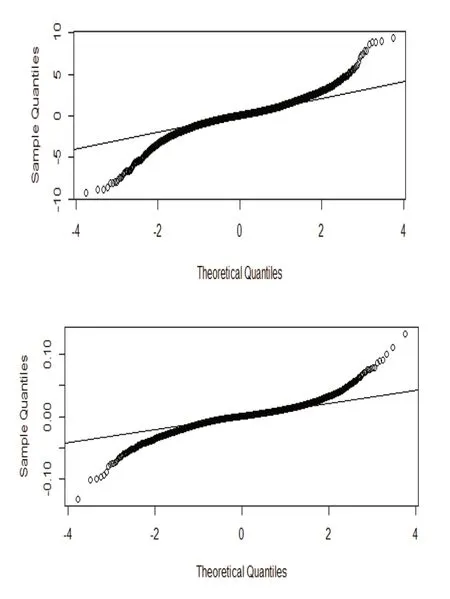
图2 SSEC与NASDAQ的日对数收益率的Q-Q图
上证综指(SSEC)和纳斯达克(NASDAQ)的平均收益率分别为0.014419、0. 000214;标准差分别为1.497660、0. 015952;最高收益率记录分别为9.400787、0. 132546;最低收益率分别为-9.256154、-0. 131492;偏度分别为-0.0379141、-0. 126644;峰度分别为5.283930、6. 084743;贾克-贝拉统计量分别为6763,9141.2;P值均小于2.2e-16。
两序列的均值接近于0,且均为正值,即其序列的波动方向一致。SSEC的标准差大于NASDAQ的标准差,即SSEC比NASDAQ的波动幅度大。从偏度值和峰度值可以看出,SSEC和NASDAQ的存在左偏现象和尖峰厚尾现象,本文使用ADF检验两序列的平稳性。
SSEC和NA SDAQ收益率序列的ADF检验显示,上证综指、纳斯达克ADF增强型迪基-富勒检验值分别为-16.165、-17.573,两个序列都是平稳的;滞后阶数(Log order)分别为17、18;P值(p-value)均为0.01,确认序列的平稳性。
本文使用自相关函数(Autocorrelation Function,ACF)和偏自相关性函数(Partial Autocorrelation Function,PACF)对SSEC和NASDAQ的收益率序列的自相关性和偏自相关性进行分析。
由图3和图4可知,SSEC和NASDAQ的收益率序列的相关系数除了几个滞后项不在95%的置信区间内外,其余滞后项均在95%的置信区间内上下浮动,即SSEC和NASDAQ的收益率序列无明显的前后相关性,也无明显的偏自相关性,可基于APARCH模型进行实证分析。

图3 SSEC的收益率序列的ACF图和PACF图

图4 NASDAQ的收益率序列的ACF图和PACF图
SSEC和NASDAQ收益率序列的J-B统计量检验结果显示,上证综指、纳斯达克J-B统计量分别为67.802,121.14;p-value分别为4.415e-07、2.22e-16。
由此可见,两序列存在ARCH效应,因此SSEC和NASDAQ可建立APARCH模型分析其波动性特征。
5 实证分析及其结论
本文在高斯分布和GED分布下基于APARCH(1,1)模型对SSEC和NASDAQ的收益率序列进行实证分析,实证结果如表1所示。

表1 SSEC收益率序列的APARCH(1,1)模型的系数
由表1可知,在GED分布下,序列满足APARCH(1,1)模型的假设条件,且参数ω和α1γ1β1的估计值均大于0,在统计意义上是高度显著的,因此可以很好地拟合SSEC的收益率序列。
在高斯分布假设下,模型的赤池信息准则(AIC)值为3. 341704;贝叶斯信息准则(BIC)值为3. 348713;施瓦茨信息准则(SIC)与AIC值相同,为3. 341702;汉南-奎因信息准则(HQIC)值为3.344144。在GED分布(广义误差分布)假设下,AIC值为3.262934,BIC值为3.271111,SIC值为3.262931,HQIC值为3.265781。
SSEC序列在高斯分布下的各值大于在GED分布下的各值,所以在GED分布下参数的估计值可作为最优的数据模型(见表2)。

表2 NASDAQ收益率序列在高斯分布和GED分布下的APARCH(1,1)模型的系数
APARCH(1,1)模型描述了NASDAQ的收益率序列的非对称性,消除了方程的异方差效应,无论是在高斯分布下还是在GED分布下,参数ω和α1γ1β1的估计值均大于0,在统计意义上是高度显著的,因此可以很好地拟合NASDAQ的收益率序列。
在高斯分布假设下,模型的赤池信息准则(AIC)值为3. 254124;贝叶斯信息准则(BIC)值为3. 260910;施瓦茨信息准则(SIC)值为3. 254122;汉南-奎因信息准则(HQIC)值为3.256483。在GED分布(广义误差分布)假设下,AIC值为3.233808,BIC值为3.241725,SIC值为3.233805,HQIC值为3.236560。
NASDAQ收益率序列基于APARCH(1,1)模型的各值大于在GED分布下的各值,所以在GED分布下参数的估计值可作为最优的数据模型。本文基于APARCH模型计算出SSEC和NASDAQ超前一步的均值和波动率,并分别计算出在置信水平为99%,99.9%和99.99%的接下来一个交易日的VaR值。
在正态分布(norm)假设下,上证综指的一步均值预测为0.0130488,纳斯达克为0.0264795。在广义误差分布(ged)假设下,上证综指的一步均值预测为0.0421737,纳斯达克为0.062526。在正态分布假设下,上证综指的预测误差为0.9007841,纳斯达克的预测误差为0.952448。在广义误差分布假设下,上证综指的预测误差为0.899533,纳斯达克的预测误差为0.939640。
(1)置信水平99%:在正态分布假设(norm)下,上证综指的VaR值为2.108586,纳斯达克为2.242204。在广义误差分布假设(ged)下,上证综指的VaR值为6.264795,纳斯达克为6.562585。
(2)置信水平99.9%:在正态分布假设下,上证综指的VaR值为2.796681,纳斯达克为2.969764。在广义误差分布假设下,上证综指的VaR值为19.881710,纳斯达克为20.786617。
(3)置信水平99.99%:在正态分布假设下,上证综指的VaR值为3.363080,纳斯达克为3.568649。在广义误差分布假设下,上证综指的VaR值为62.508831,纳斯达克为65.314287。
根据上述分析,可得出以下结论:
第一,两序列在同一种分布下时,VaR随置信水平的提升而增加,所以投资者在投资决策时,如果参考了较低置信水平下的风险价值,结果就会比较保守,可以有效地规避风险;如果参考了较高置信水平下的风险价值,结果就会比较激进,可以获得高收益。
第二,在相同的置信水平和分布下,SSEC预测的超前一步的VaR低于NASDAQ预测的超前一步的VaR,说明中国股市相较美国股市风险更低。
第三,利用SSEC和NASDAQ序列基于APARCH模型在高斯分布下得到的预测值普遍低于在GED分布下得到的预测值,且随着置信水平逐步提升,在GED分布下可以更好地展现收益率序列的尖峰厚尾性。
猜你喜欢
数字通信世界(2021年3期)2021-04-09
湖北理工学院学报(2020年4期)2020-08-22
经济研究导刊(2020年15期)2020-06-21
山东工业技术(2018年18期)2018-10-31
计算机应用与软件(2017年4期)2017-04-24
大经贸(2017年1期)2017-03-17
股市动态分析(2016年11期)2016-10-11
股市动态分析(2016年10期)2016-09-30
股市动态分析(2016年25期)2016-07-23
股市动态分析(2015年35期)2015-09-10
